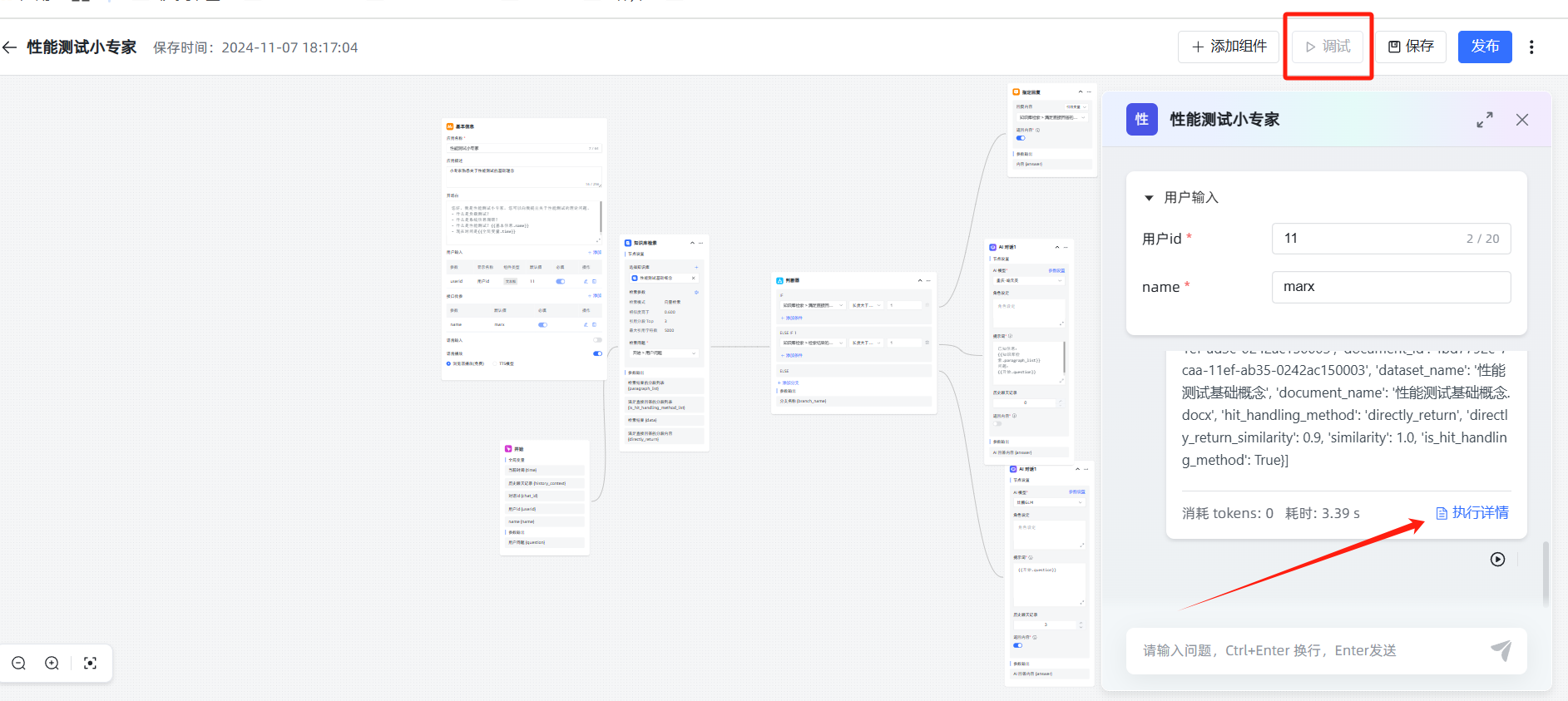
可以在应用设置里“调试”,然后查看执行详情,确认AI对话时分段内容是不是完整的。
因为应用里的图片地址是在你们MaxKB服务器上面,或者是你们内网的图片地址,钉钉应该访问不到。
但是我们做的有公网映射啊,别人访问我们应用提供的url,也会正常出来知识库中的图片,唯独钉钉机器人不会展示照片 ![]()
![]()
好像是钉钉那边要审核,大概等了一天左右,知识库的照片可以正常输出了 ![]()
原来如此 ![]()
哥们,有没有第三方适合AI查询的平台啊推荐一下(通过api key可以让本地模型具有联网能力的,比如博查ai这种的(博查爬的信息感觉还是不行),想问问恁这边有没有推荐的) ![]()
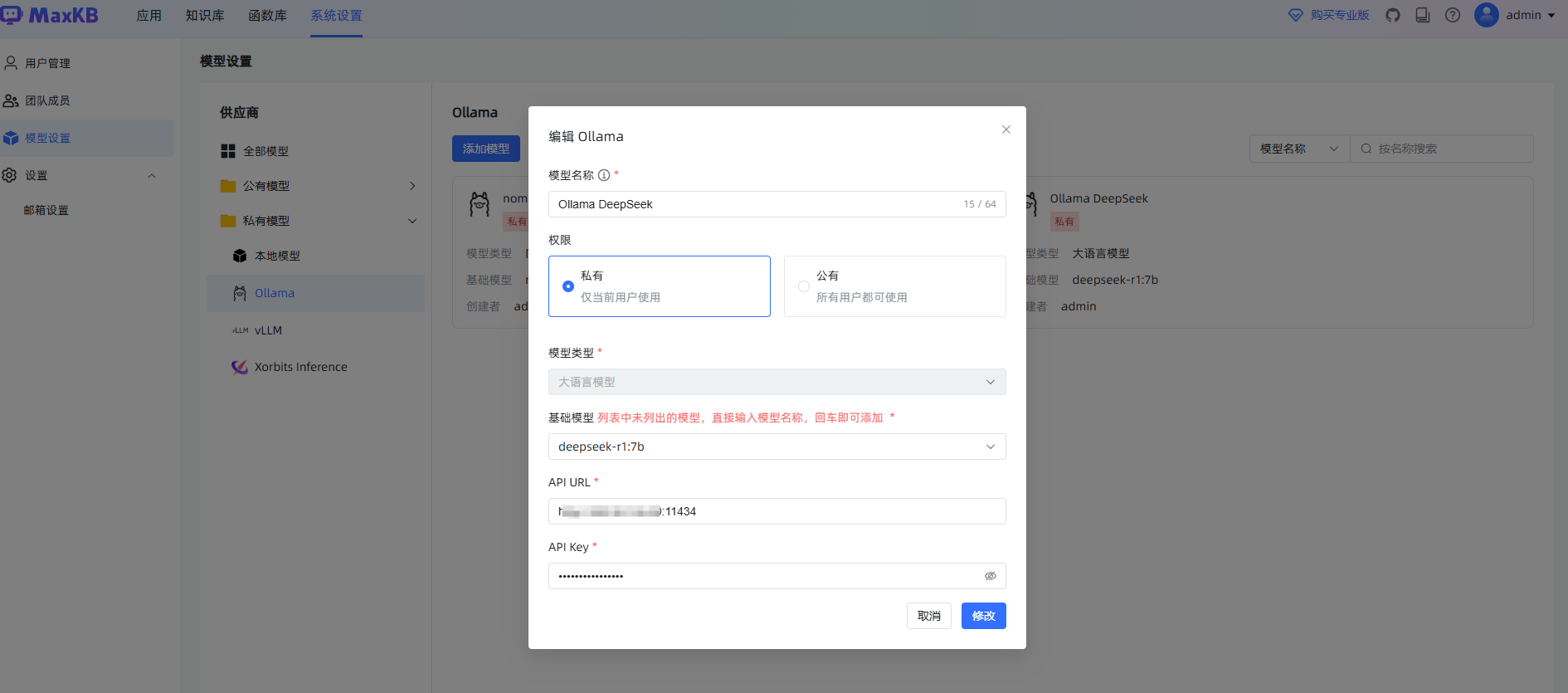
问题求助:添加本地大语言模型,Ollama deepseek的API key应该怎么填,不能为空,但是我并没有设置任何API key。使用curl调用ollama的API也可以成功,也没有使用任何key。
$ ollama list
NAME ID SIZE MODIFIED
nomic-embed-text:latest 0a109f422b47 274 MB 29 seconds ago
deepseek-r1:7b 0a8c26691023 4.7 GB 18 hours ago
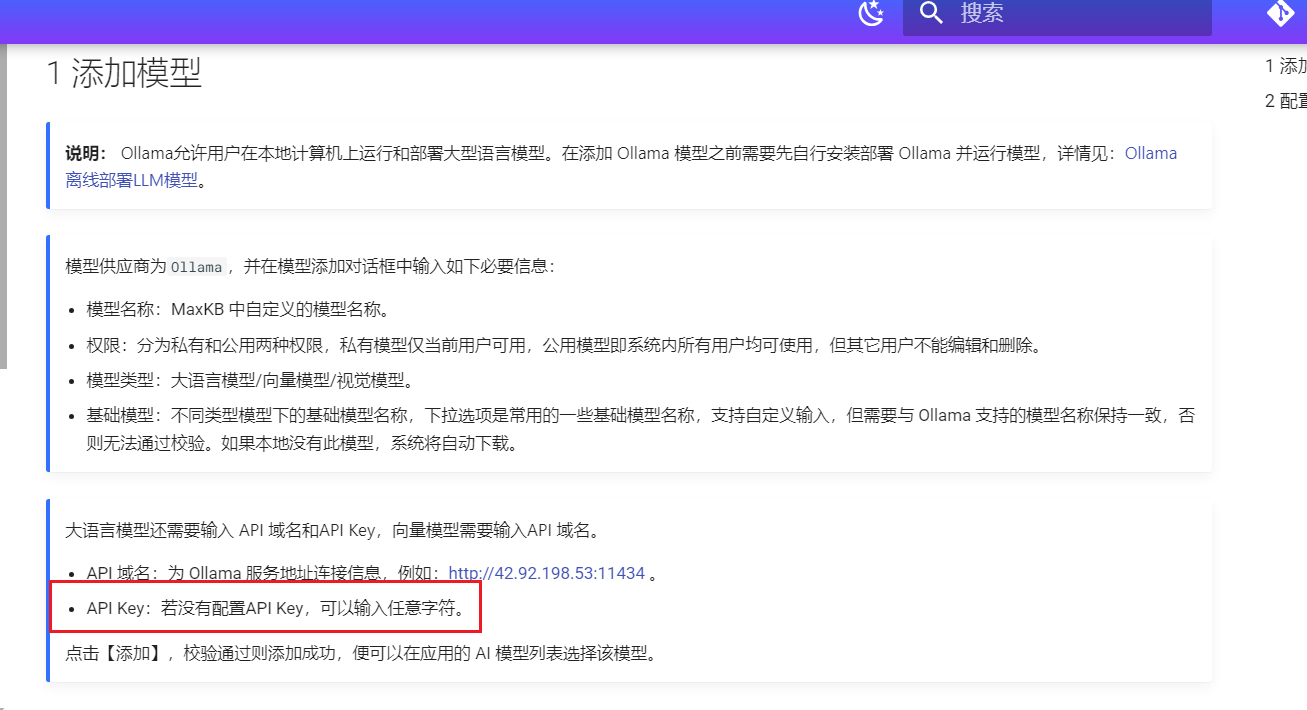
问题:本地部署「DeepSeek」模型硬件配置要求
答复:转载自:https://mp.weixin.qq.com/s/JuJo5icr-HXyA5tBHsPzrg
参数模型硬件要求
以下是不同参数量模型的本地部署硬件要求和适用场景分析。注:部分数据基于模型通用需求推测,具体以实际部署测试为准。
![]() DeepSeek-R1-1.5B
DeepSeek-R1-1.5B
- CPU: 最低 4 核(推荐 Intel/AMD 多核处理器)
- 内存: 8GB+
- 硬盘: 3GB+ 存储空间(模型文件约 1.5-2GB)
- 显卡: 非必需(纯 CPU 推理),若 GPU 加速可选 4GB+ 显存(如 GTX 1650)
- 场景: 低资源设备部署,如树莓派、旧款笔记本、嵌入式系统或物联网设备
![]() DeepSeek-R1-7B
DeepSeek-R1-7B
- CPU: 8 核以上(推荐现代多核 CPU)
- 内存: 16GB+
- 硬盘: 8GB+(模型文件约 4-5GB)
- 显卡: 推荐 8GB+ 显存(如 RTX 3070/4060)
- 场景: 中小型企业本地开发测试、中等复杂度 NLP 任务,例如文本摘要、翻译、轻量级多轮对话系统
![]() DeepSeek-R1-8B
DeepSeek-R1-8B
- CPU: 8 核以上(推荐现代多核 CPU)
- 内存: 16GB+
- 硬盘: 8GB+(模型文件约 4-5GB)
- 显卡: 推荐 8GB+ 显存(如 RTX 3070/4060)
- 场景: 需更高精度的轻量级任务(如代码生成、逻辑推理)
![]() DeepSeek-R1-14B
DeepSeek-R1-14B
- CPU: 12 核以上
- 内存: 32GB+
- 硬盘: 15GB+
- 显卡: 16GB+ 显存(如 RTX 4090 或 A5000)
- 场景: 企业级复杂任务、长文本理解与生成
![]() DeepSeek-R1-32B
DeepSeek-R1-32B
- CPU: 16 核以上(如 AMD Ryzen 9 或 Intel i9)
- 内存: 64GB+
- 硬盘: 30GB+
- 显卡: 24GB+ 显存(如 A100 40GB 或双卡 RTX 3090)
- 场景:高精度专业领域任务、多模态任务预处理
![]() DeepSeek-R1-70B
DeepSeek-R1-70B
- CPU: 32 核以上(服务器级 CPU)
- 内存: 128GB+
- 硬盘: 70GB+
- 显卡: 多卡并行(如 2x A100 80GB 或 4x RTX 4090)
- 场景: 科研机构/大型企业、高复杂度生成任务
![]() DeepSeek-R1-671B
DeepSeek-R1-671B
- CPU: 64 核以上(服务器集群)
- 内存: 512GB+
- 硬盘: 300GB+
- 显卡: 多节点分布式训练(如 8x A100/H100)
- 场景: 超大规模 AI 研究、通用人工智能(AGI)探索
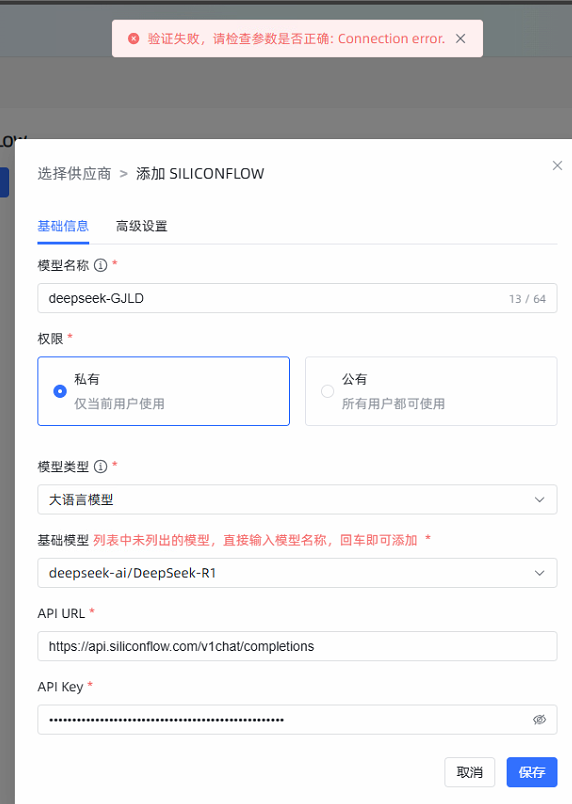

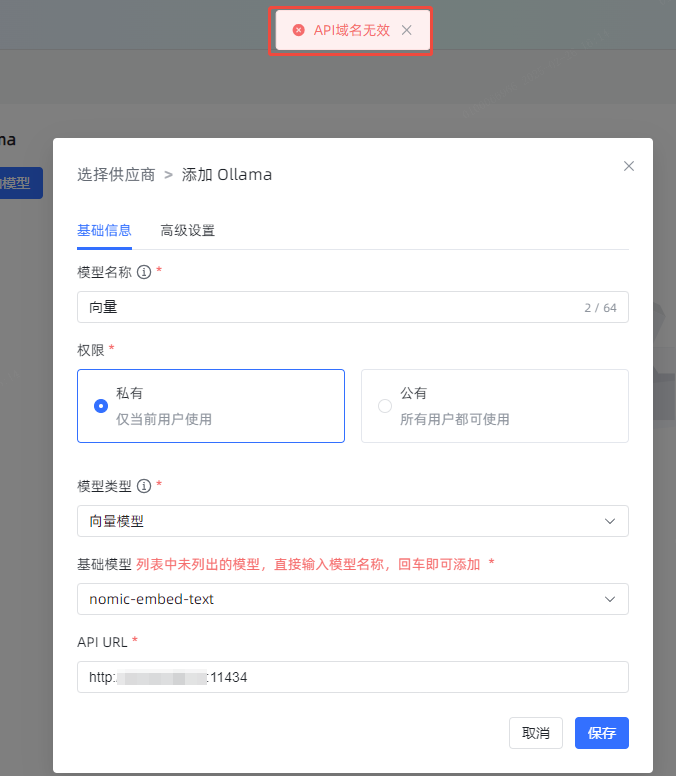
域名不对,参考下官网文档。
百炼的R1,有时候感觉不稳定,我这边偶尔会这样,思考中也会经常卡顿。
我是用云上的API,感觉maxkb流式输出很不稳定,偶尔卡顿,但看云上部署的又很快,不确定是不是调用的网络问题
1 个赞
问题:本地计算机ubtu22.04 非模拟器 显卡GTX1070 安装ollama模型 始终无法调用GPU资源。请问怎么解决需要安装那些?试了cuda toolkit 和nvdia toolkit都没解决到问题 整崩溃了。
如何去除think标签及里面的内容?
求教,调用deepseek API时如何开启联网搜索呢