欢迎大家把自己使用的函数跟帖分享,帖子内容可参考如下:
一、函数名称:****
二、函数代码:
1、依赖:
2、函数编写:
3、输入变量定义:
三、使用方法及效果:
欢迎大家把自己使用的函数跟帖分享,帖子内容可参考如下:
一、函数名称:****
二、函数代码:
1、依赖:
2、函数编写:
3、输入变量定义:
三、使用方法及效果:
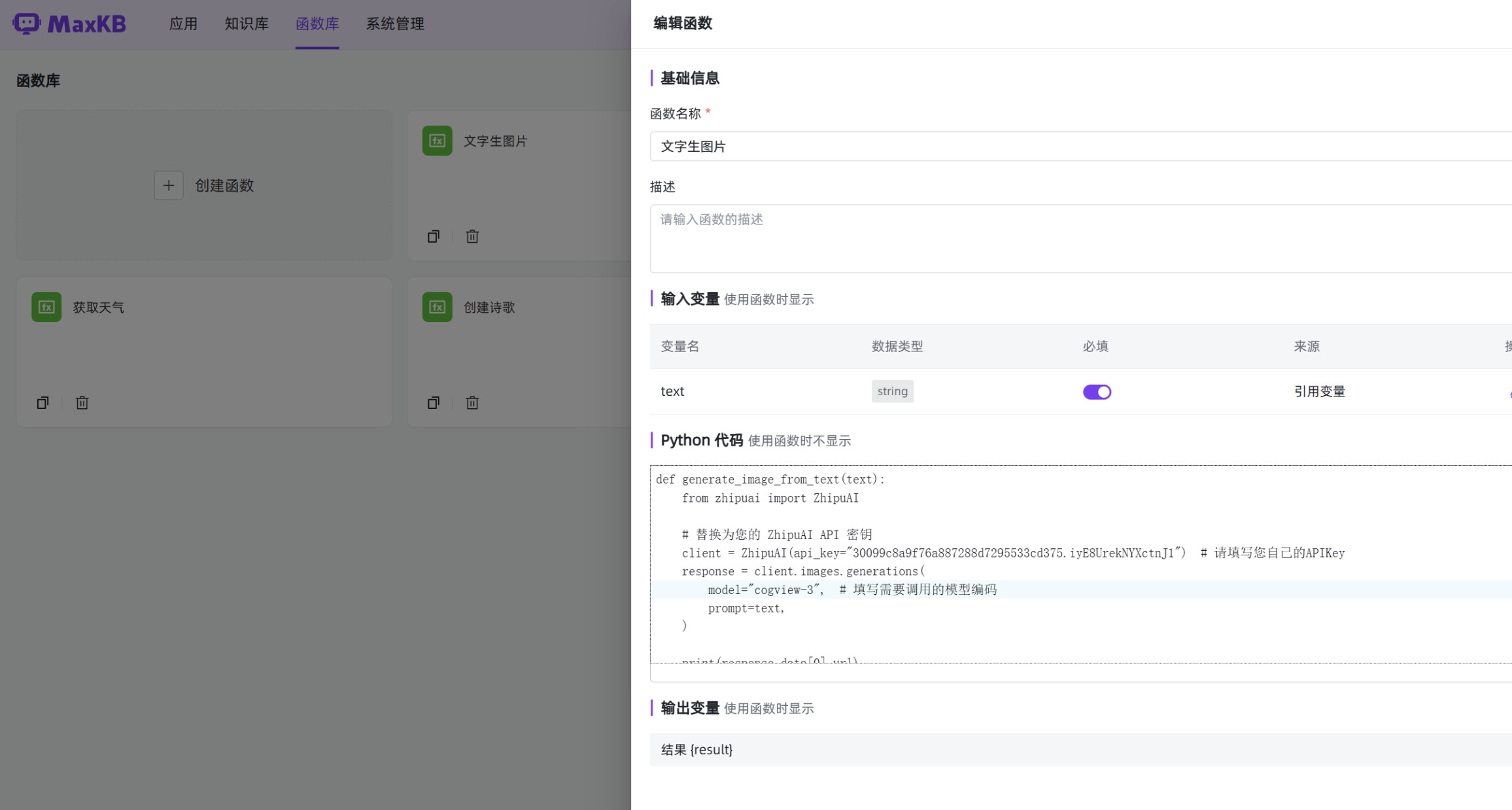
一、函数名称: 使用 MaxKB 实现文字自动生成图片
二、函数代码:
1、依赖:借助智谱 AI 的 CogView 图像大模型实现,首先请通过如下方式进行安装Python SDK 包:
pip install zhipuai
2、函数编写:
defgenerate_image_from_text(text):
fromzhipuaiimportZhipuAI
# 替换为您的 ZhipuAI API 密钥
client=ZhipuAI(api_key="30099c8**************")# 填写自己的APIKey
response=client.images.generations(
model="cogview-3",# 填写需要调用的模型编码
prompt=text,
)
(response.data[0].url)
url=response.data[0].url
returnf''
3、定义输入变量:
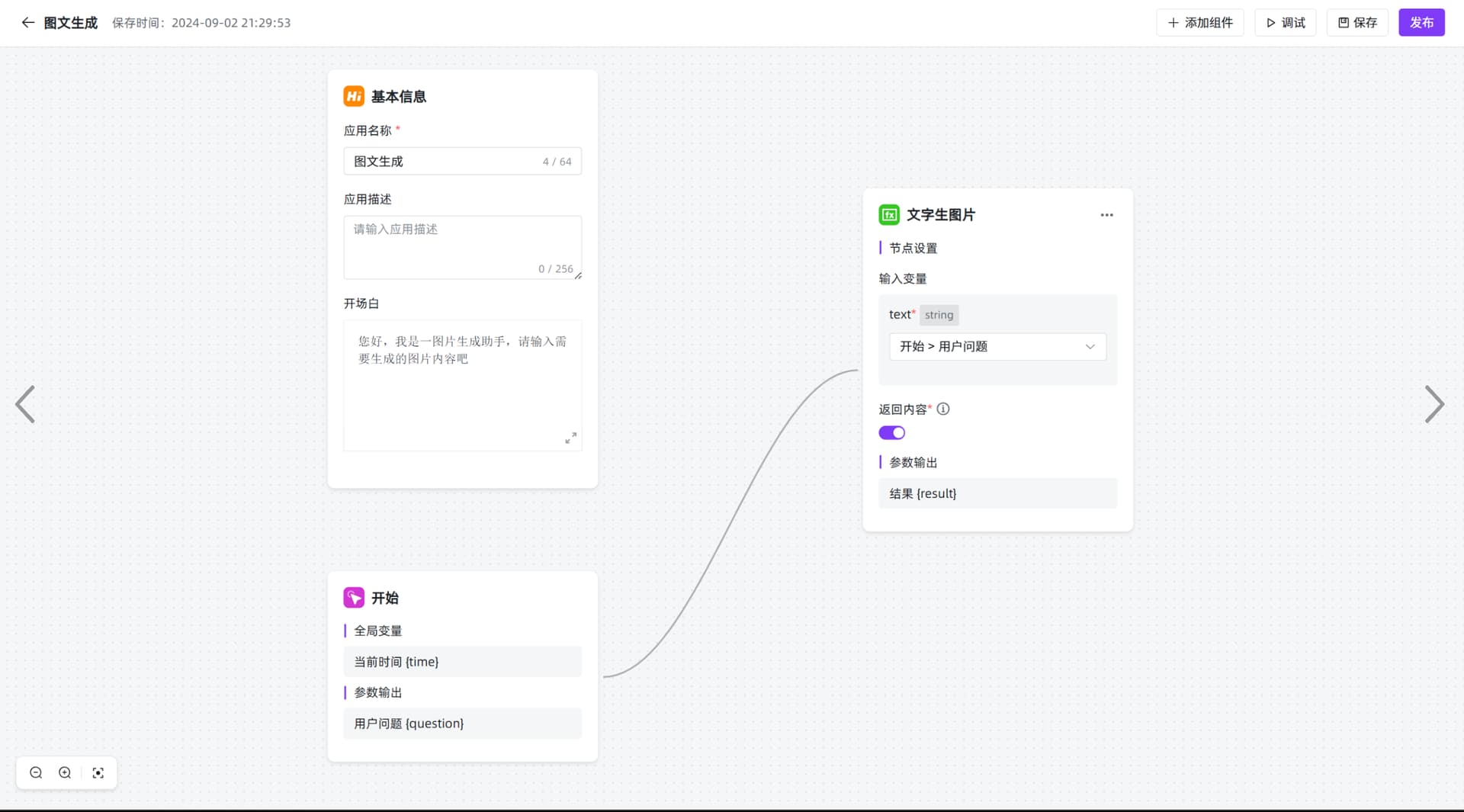
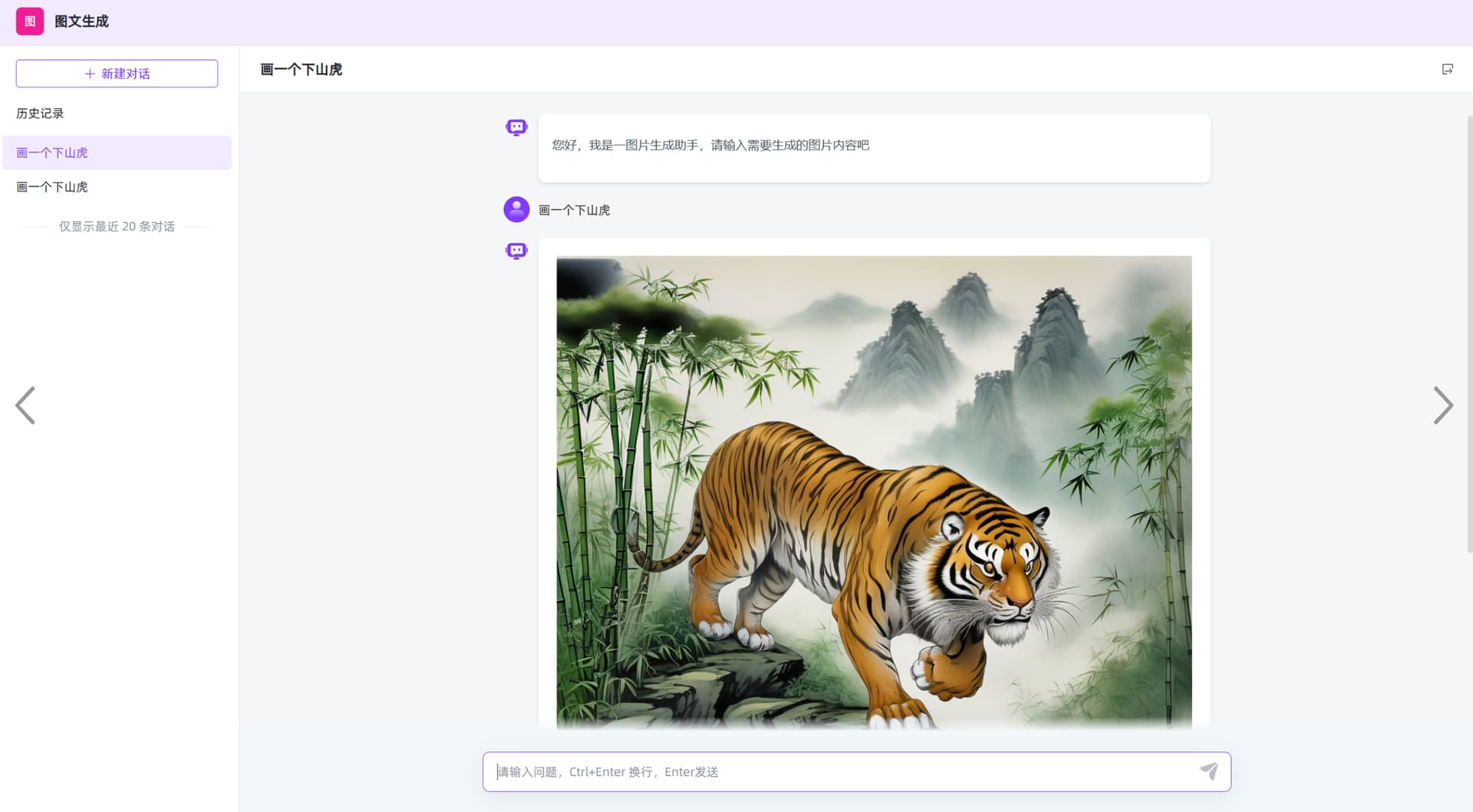
三、使用效果:
第一步:应用编排流程中添加文字生成图片的函数库
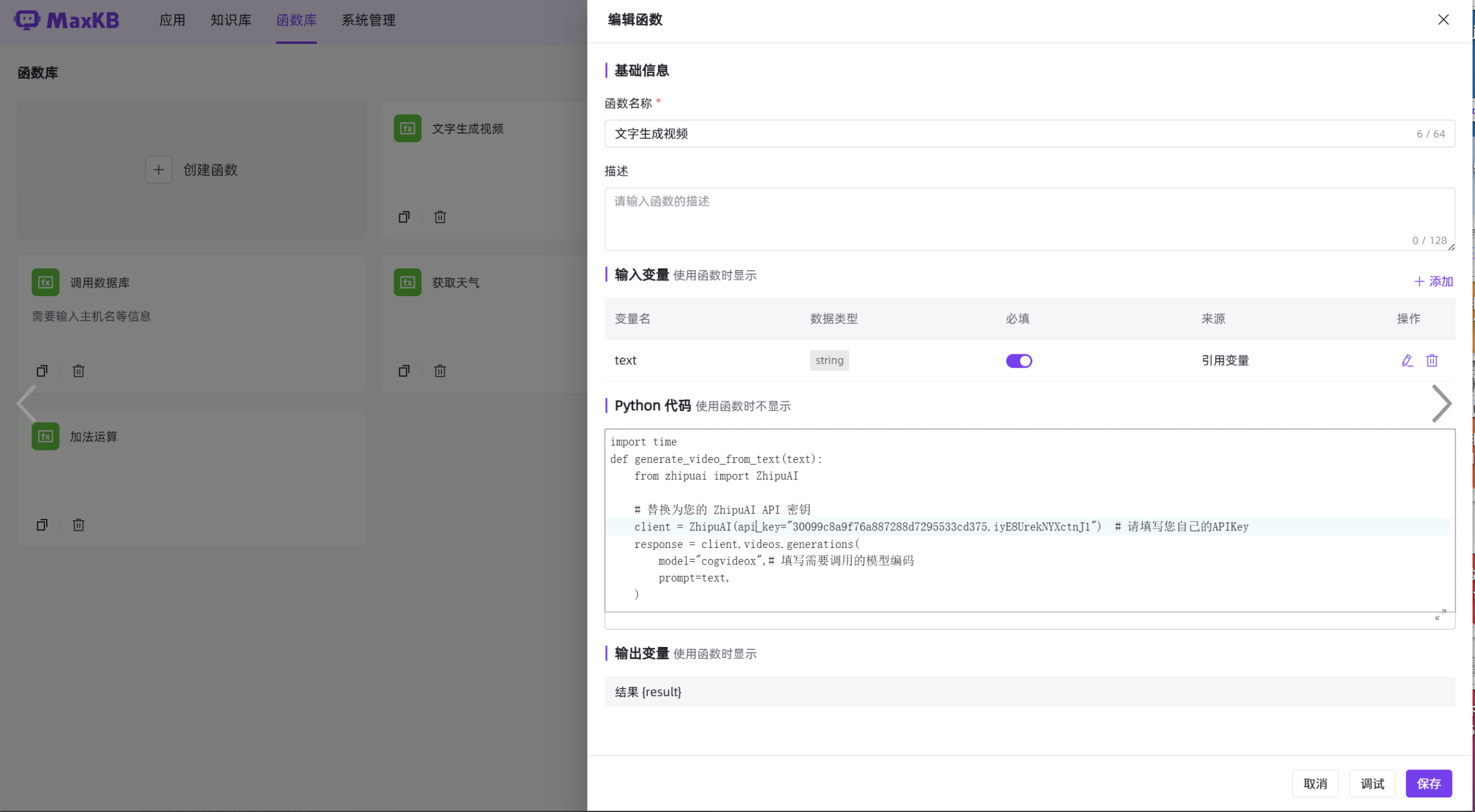
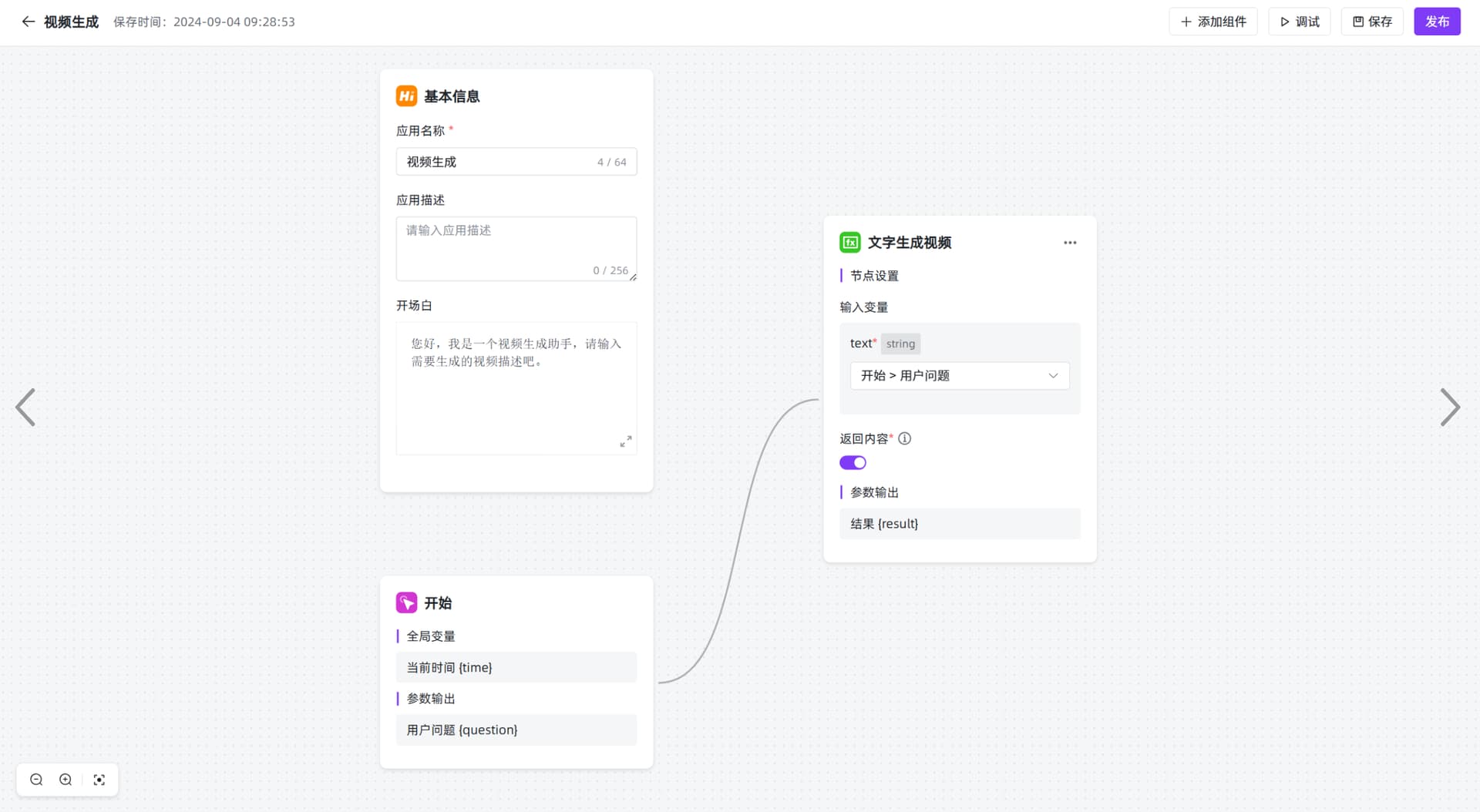
一、函数名称: 使用 MaxKB 实现文字自动生成视频
二、函数代码:
1、依赖:借助智谱 AI 的 CogView 图像大模型实现,首先请通过如下方式进行安装Python SDK 包:
pip install zhipuai
2、函数编写:
import time
def generate_video_from_text(text):
from zhipuai import ZhipuAI# 替换为您的 ZhipuAI API 密钥 client = ZhipuAI(api_key="30099c8a9f7******************") # 请填写您自己的APIKey response = client.videos.generations( model="cogvideox",# 填写需要调用的模型编码 prompt=text, ) task_id = response.id task_status = '' get_cnt = 0 while task_status != 'SUCCESS' and task_status != 'FAILED' and get_cnt <= 200: result_response = client.videos.retrieve_videos_result(id=task_id) print(result_response) task_status = result_response.task_status time.sleep(2) get_cnt += 1 if task_status == 'SUCCESS': url = result_response.video_result[0].url print(result_response.video_result[0].url) return f'<video controls width=500 height=300 src="{url}" frameborder="0" scrolling="no" allowfullscreen="true" alt="占位视频"></video>' else: return '任务成功但未找到视频结果'
3、定义输入变量:
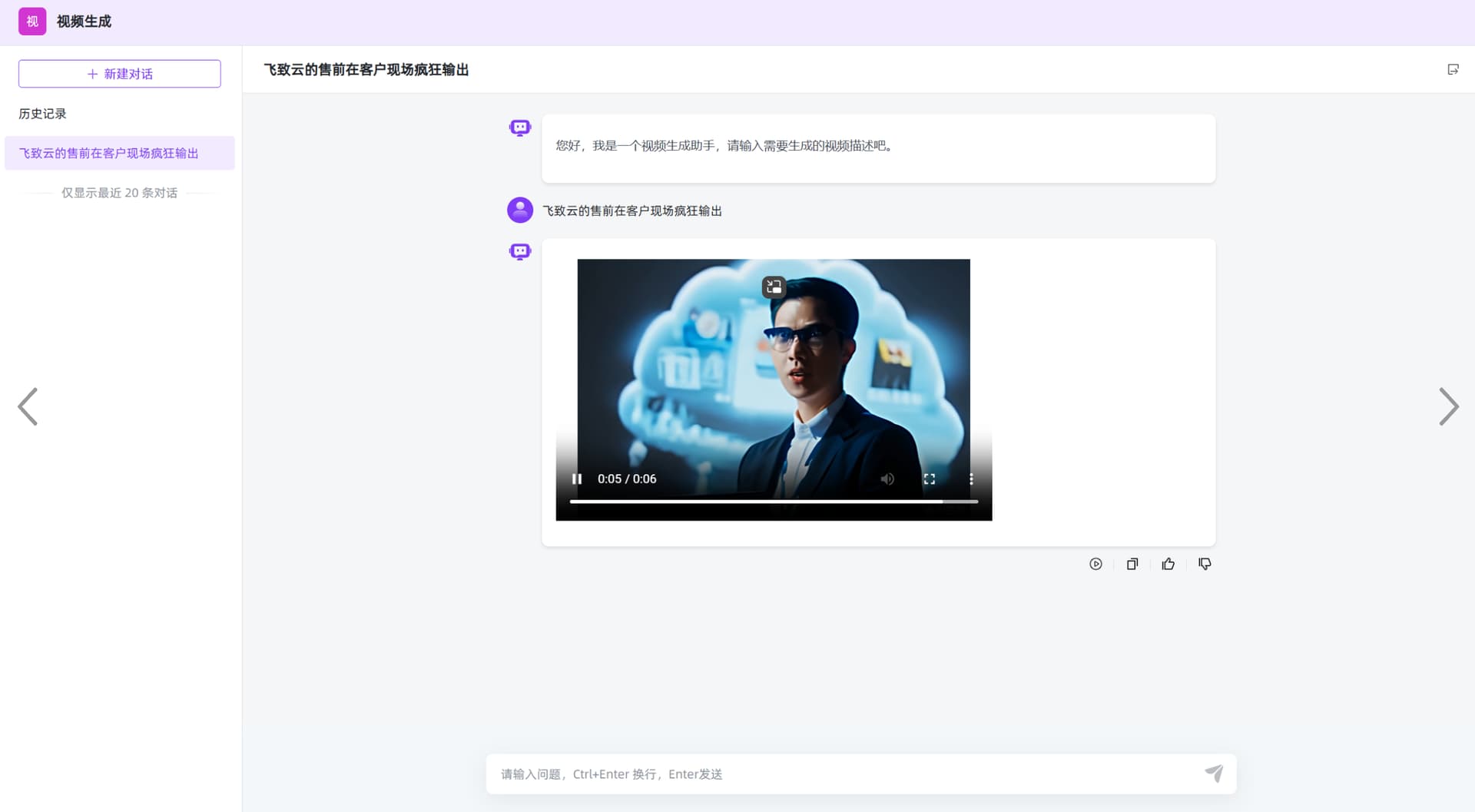
三、使用效果:
第一步:应用编排流程中添加文字生成视频的函数库
HTTP 请求函数 和 MySQL数据库连接函数 参见以下链接
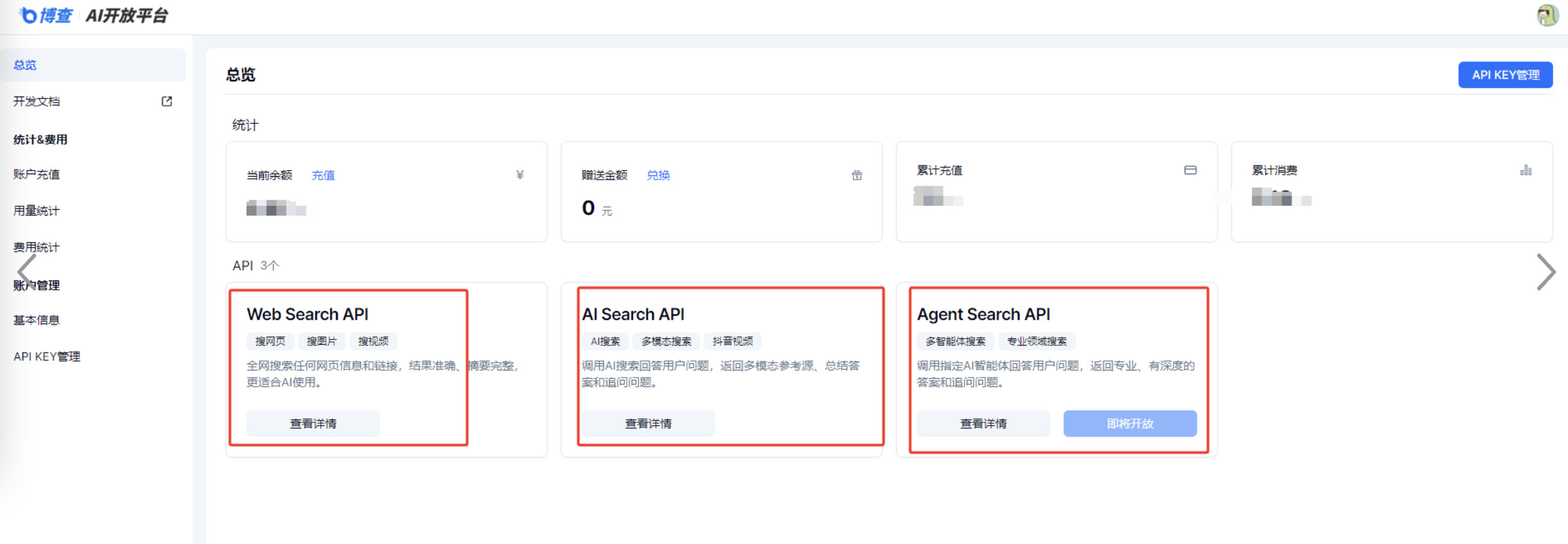
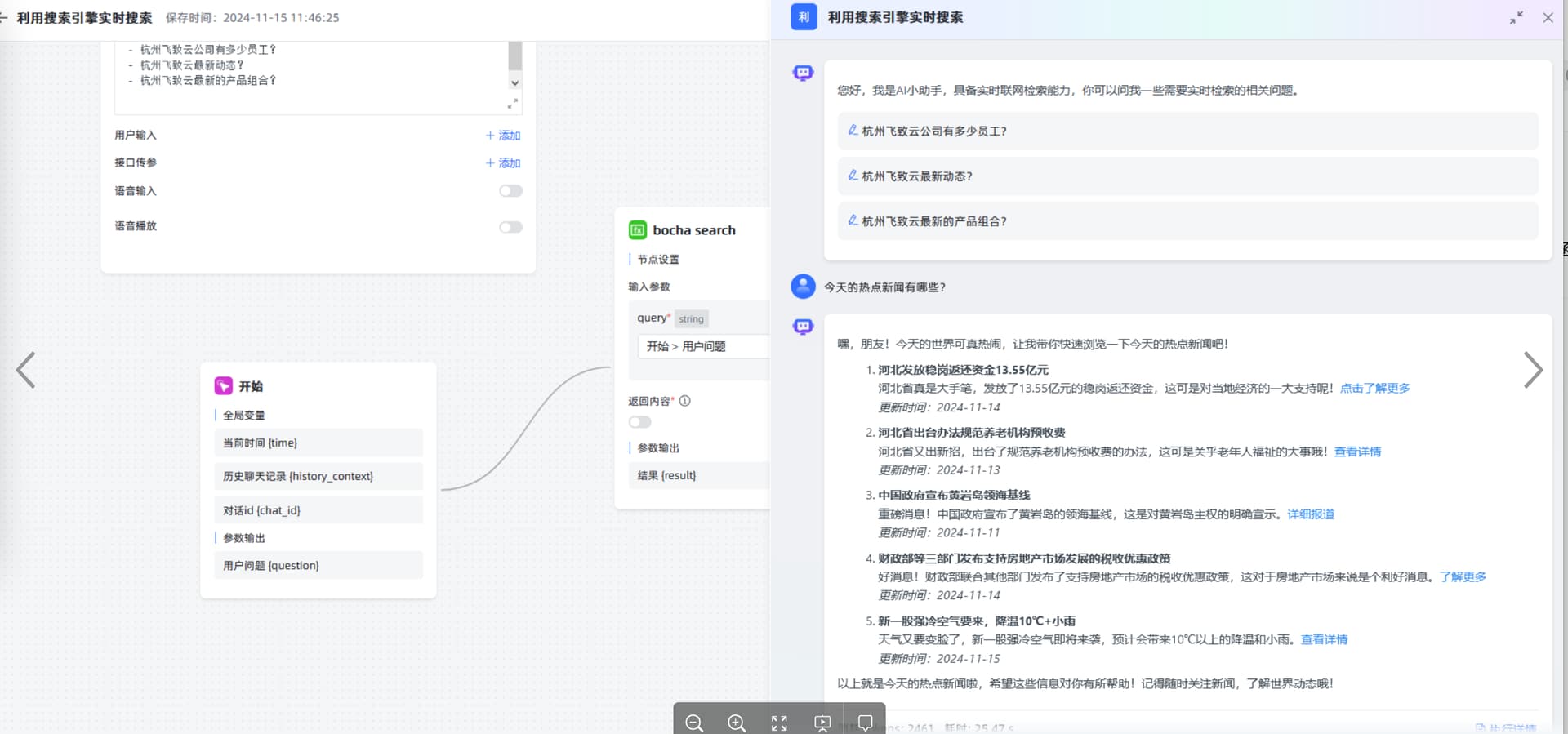
一、函数名称: MaxKB 博查搜索函数库,实时检索能力
国内的AI搜索引擎-博查AI搜索,一个基于大模型和实时搜索技术的答案引擎。你可以用自然语言提问,它会理解问题、细分检索并直接生成准确的答案。目前提供三种搜索能力,价格也不贵。MaxKB函数只需要Web Search API即可,费用大概是4分钱查询一次。
二、函数代码:
> def bocha_search(query):
> import requests
> import json
> url = "https://api.bochaai.com/v1/web-search"
> payload = json.dumps({
> "query": query,
> "Boolean": 'true',
> "count": 8
> })
>
> headers = {
> 'Authorization': 'Bearer sk-xxxxxxxxx', #鉴权参数,示例:Bearer xxxxxx,API KEY请先前往博查AI开放平台(https://open.bochaai.com)> API KEY 管理中获取。
> 'Content-Type': 'application/json'
> }
>
> response = requests.request("POST", url, headers=headers, data=payload)
> return response.json()
三、使用方法与效果
通过这个生成的图片,可以直接在对话中点击放大吗?
等v1.10.2-LTS版本发布后就可以放大了。
太好了。谢谢
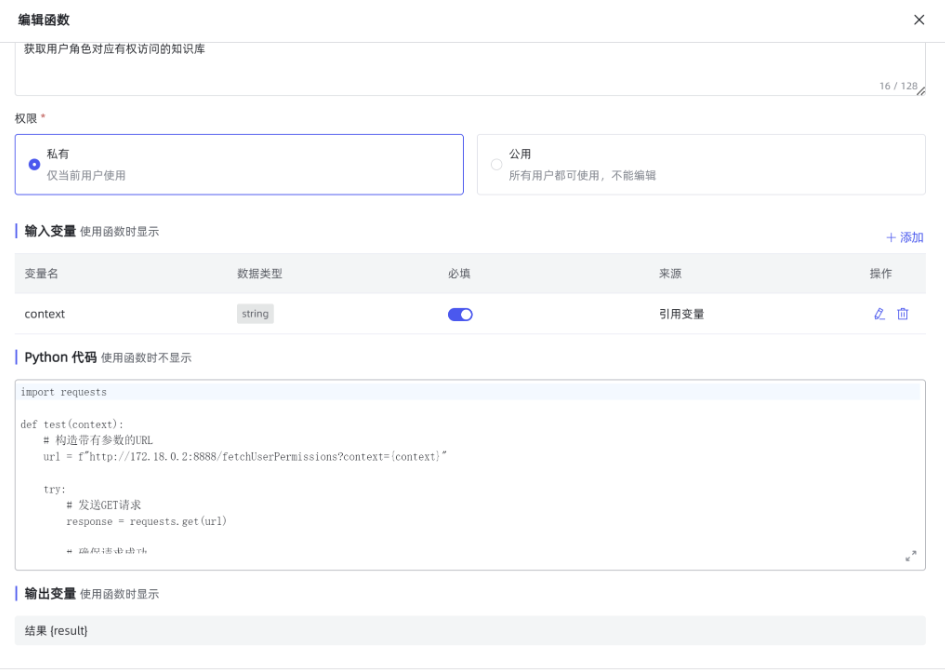
2.1 函数一:添加获取用户权限的函数
功能说明:根据函数根的输入变量将用户信息传入,并通过接口获取其对应的可以访问的知识库的名称。
函数代码:
import requests
def test(context):
# 构造带有参数的URL
url = f"http://172.18.0.2:8888/fetchUserPermissions?context={context}"
try:
# 发送GET请求
response = requests.get(url)
# 确保请求成功
response.raise_for_status()
# 返回响应的内容,假设返回的是字符串
return response.text
except requests.exceptions.RequestException as e:
# 如果发生网络错误或其他异常,打印错误信息
print(f"An error occurred: {e}")
return None
变量参数:
请求服务:
该请求对应的服务是一个最基础的基于 SpringBoot 的 Java 项目 接口代码如下:
@GetMapping("/fetchUserPermissions" )
@ResponseBody
public String fetchUserPermissions(@RequestParam(name = "context") String context) {
System.out.println("参数为 : " + context);
switch (context){
case "文员":
return "文员知识库";
case "程序员":
return "程序员知识库";
}
return "无";
}
已经部署运行在Docker中。
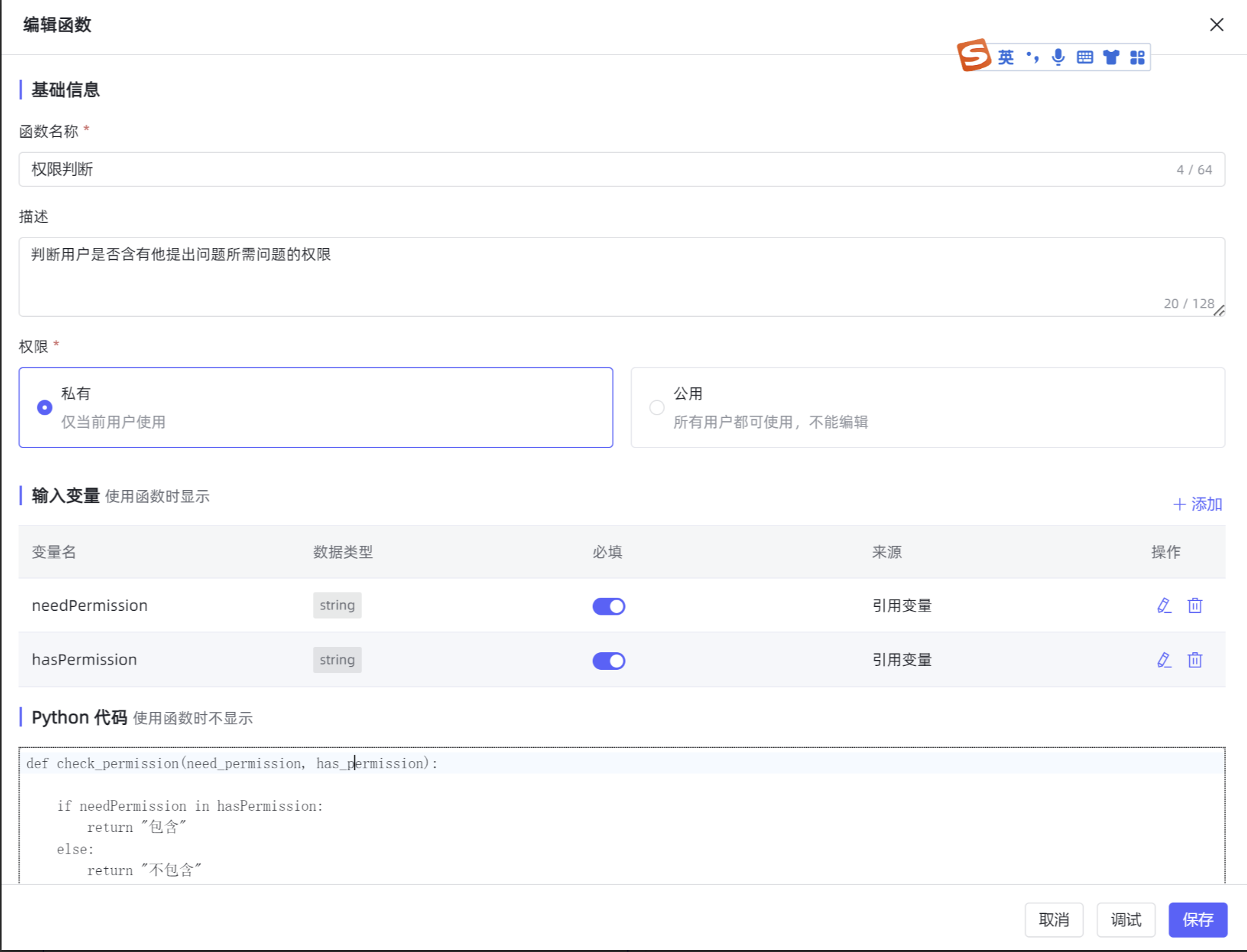
2.1 函数二:权限判断函数
功能说明:用于判断用户拥有的权限 是否 包含其提问所需的权限。
函数代码:
def check_permission(need_permission, has_permission):
if needPermission in hasPermission:
return "包含"
else:
return "不包含"
变量参数:
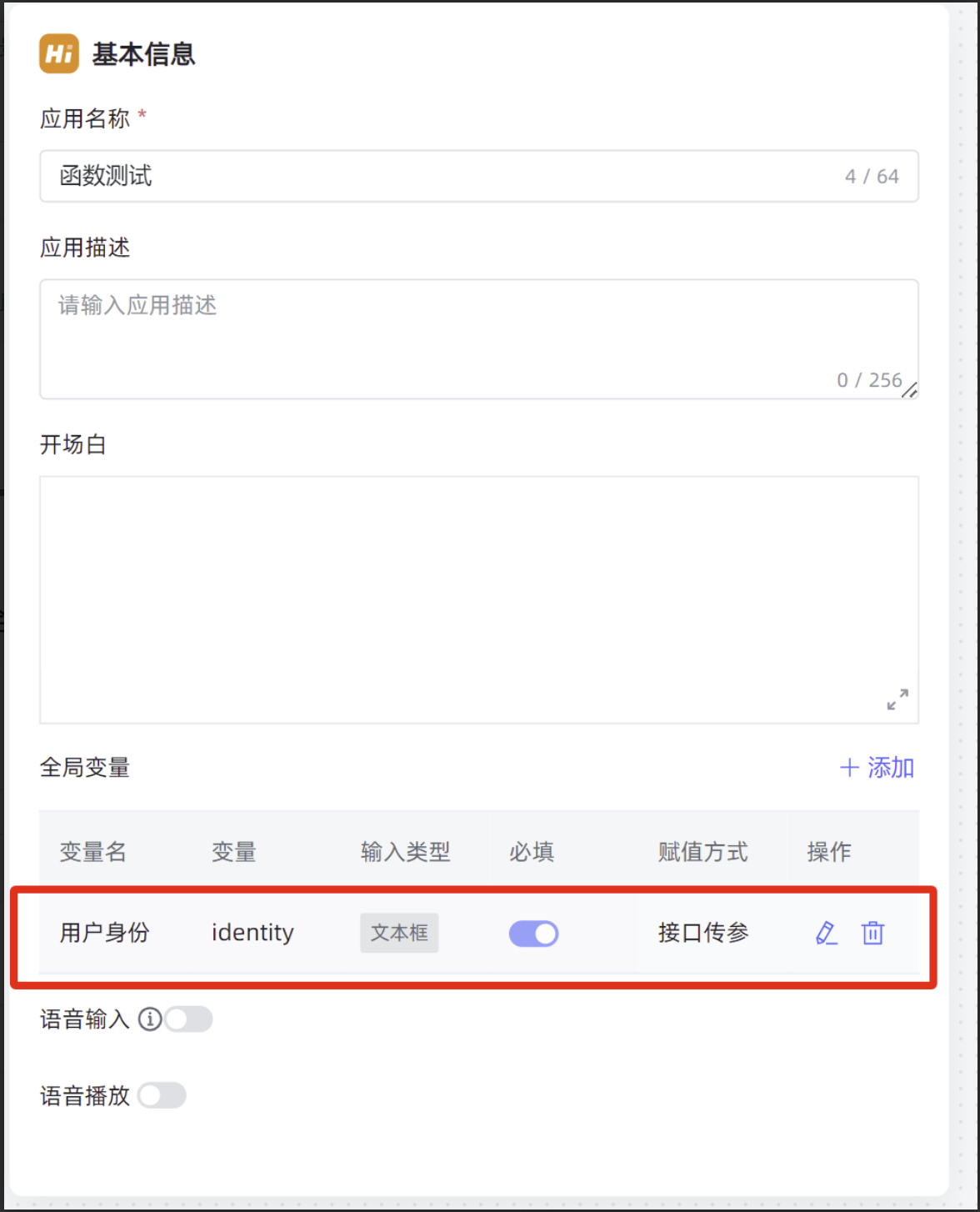
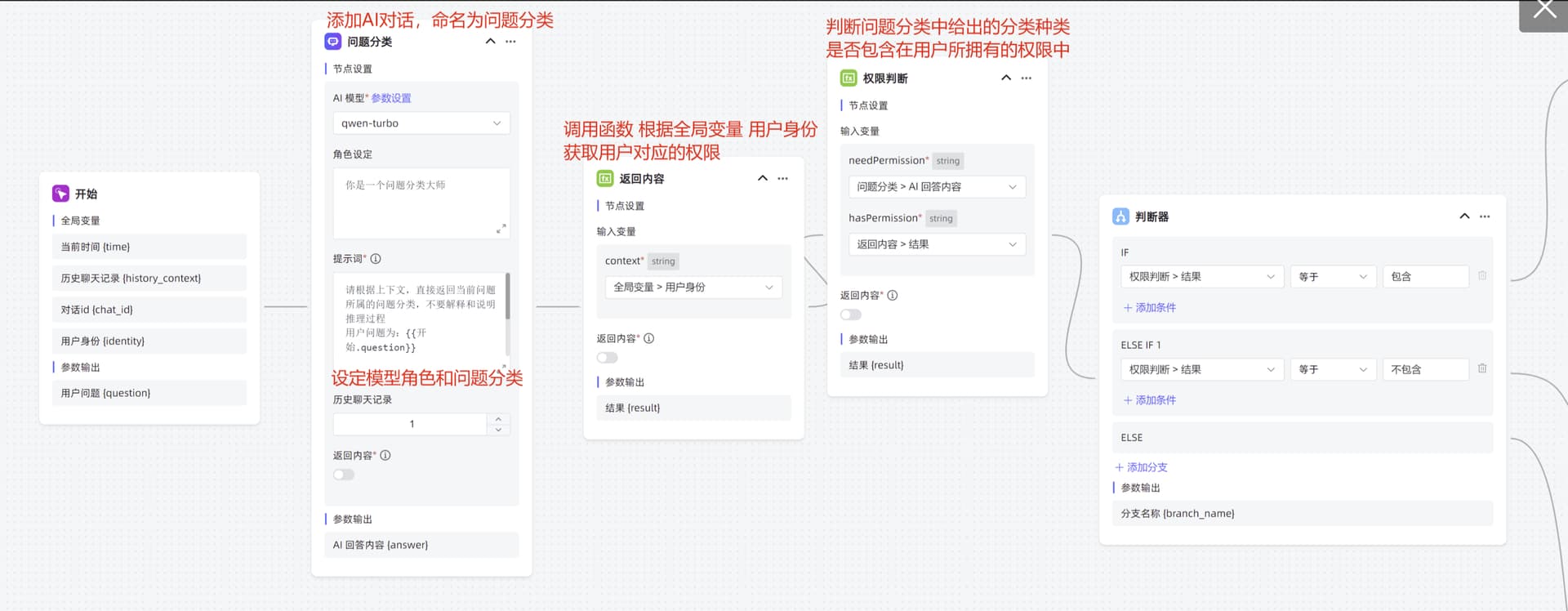
**步骤一:**创建一个高级编排的应用,在基本信息中配置全局变量,并选择赋值方式为接口传参。
**步骤二:**编排工作流
用户提出问题后增加问题分类及权限判断:
a 通过 AI 对话组件获取用户问题的分类
b 使用函数库已经添加的函数 用户权限 根据全局变量的传来的值获取用户对应的权限
c 使用权限判断函数 判断用户问题所属的类型是否被包含在该用户所拥有的权限中。
根据权限判断结果分别进行答复:
a 如果用户拥有对应知识库的权限则 指向下一个判断器 根据AI对问题的类型判断 指向对应的知识库进行回答索引
b 如果用户没有相应知识库的权限则返回既定回答
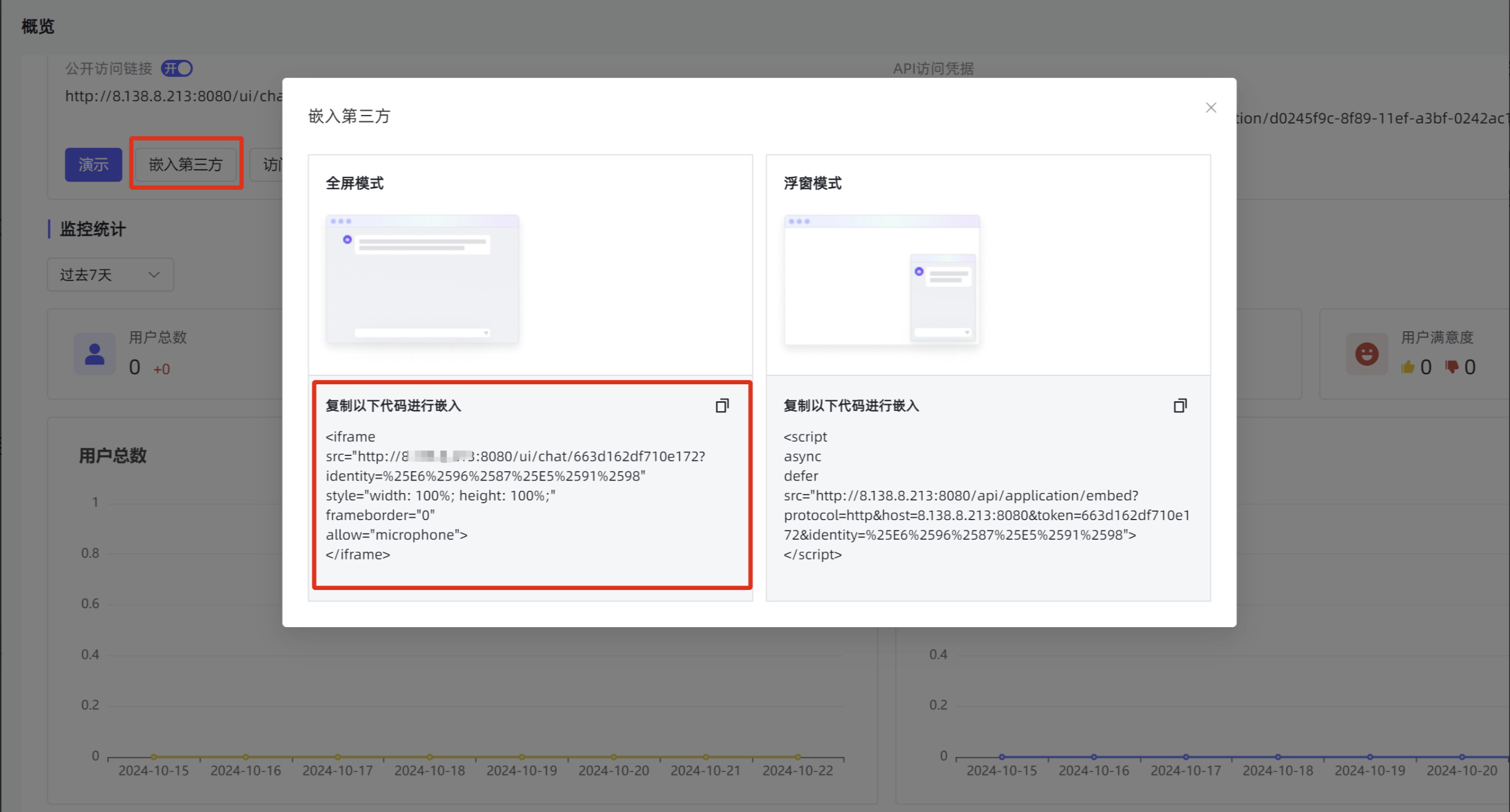
**步骤三:**进入应用点击嵌入第三方兵复制全屏模式代码潜入。
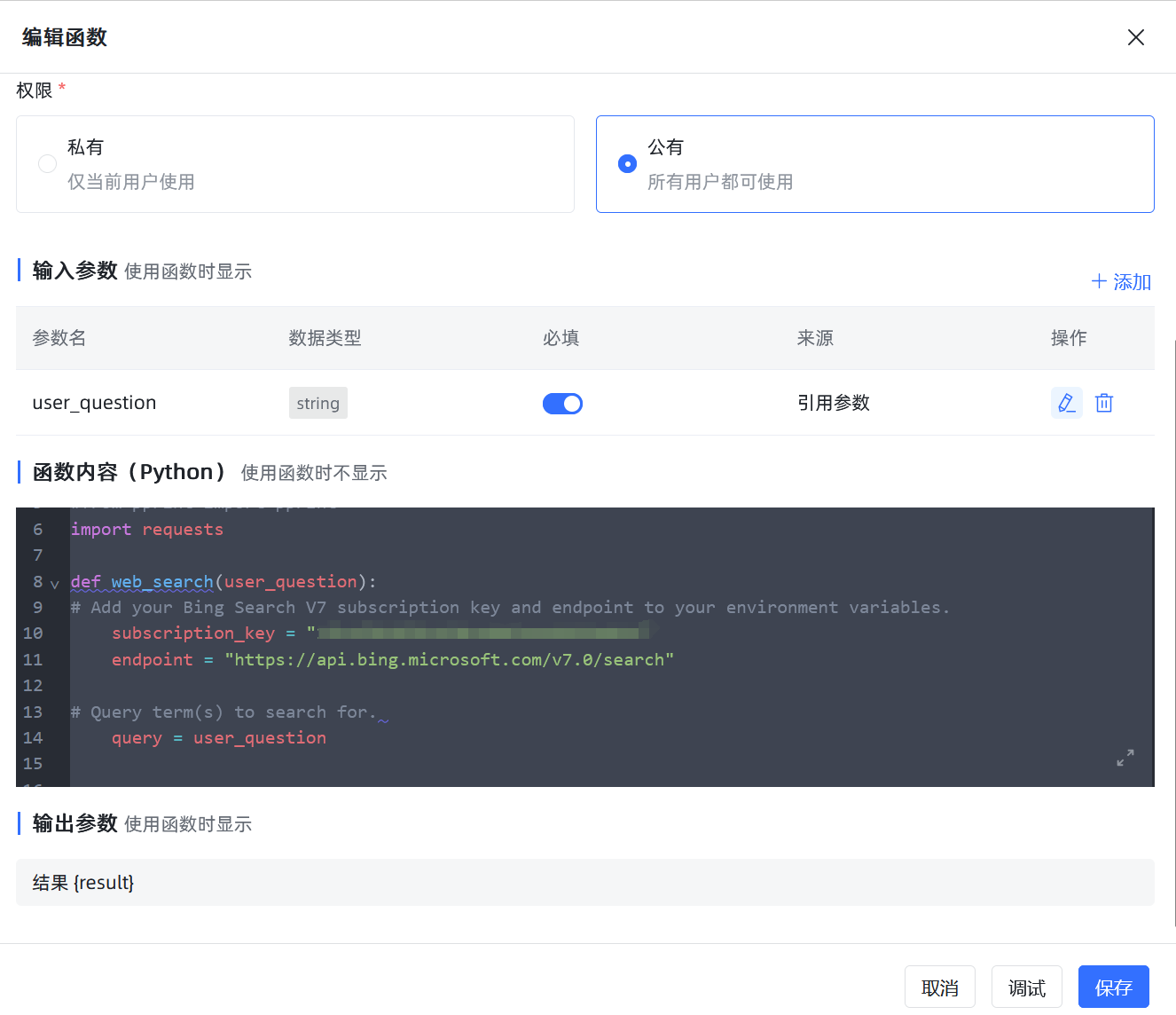
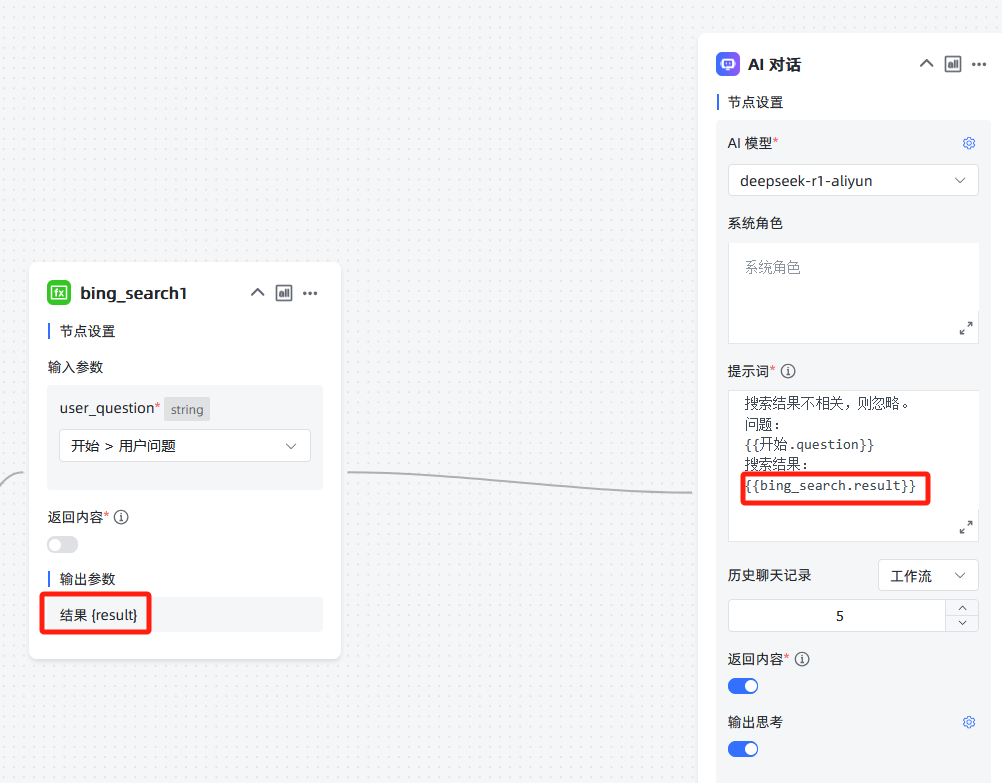
一、函数名称:Bing搜索函数
二、函数代码:
1、依赖:需要使用必应搜索API功能,我这里是azure企业账号开通的必应搜索。
2、函数编写:
# -*- coding: utf-8 -*-
import json
import os
#from pprint import pprint
import requests
def web_search(user_question):
# Add your Bing Search V7 subscription key and endpoint to your environment variables.
subscription_key = "17b1f85df85c450c*************"
endpoint = "https://api.bing.microsoft.com/v7.0/search"
# Query term(s) to search for.
query = user_question
# Construct a request
mkt = 'zh-CN'
params = { 'q': query, 'mkt': mkt }
headers = { 'Ocp-Apim-Subscription-Key': subscription_key }
# Call the API
try:
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
#print("JSON Response:")
#pprint(response.json())
return response.json()
except Exception as ex:
pass
3、输入变量定义:
定义输入变量,参数名user_question,来源选择"引用参数":
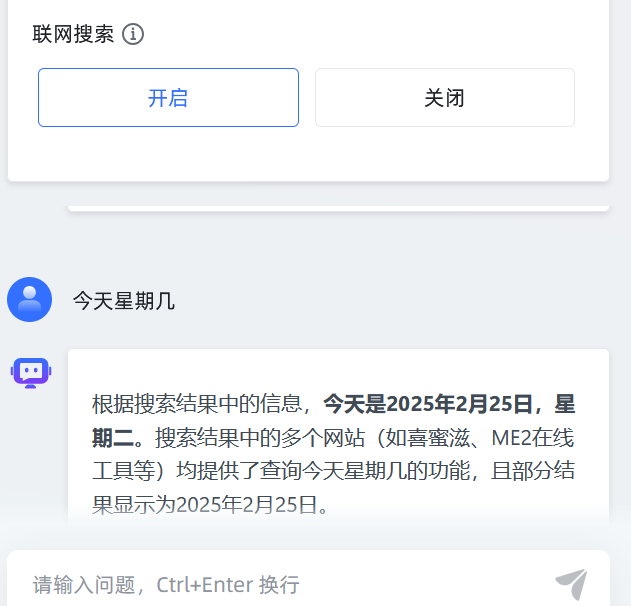
三、使用方法及效果:
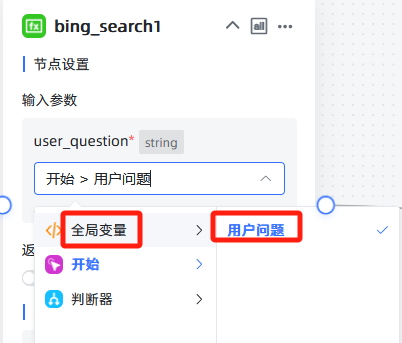
调用函数,输入参数选择"全局变量->用户问题":
把搜索结果变量添加到大模型的prompt提示词中:
回答效果:
您好,函数中的这部分代码参数需要调整下:
url = "https://api.bochaai.com/v1/web-search" payload = json.dumps({ "query": query, "summary": True, "count": 10 })
这样可以获取到response中的文本摘要,比snippet要全的很多。
另外如果使用ai search api的话,可以这样设置:
url = "https://api.bochaai.com/v1/ai-search" payload = json.dumps({ "query": query, "count": 10, #最大支持50条 "answer": False, "stream": False })
这样可以关闭他们的大模型总结和流式输出,1s就会返回结果
必应搜索API是免费的么?
大佬。你这函数return f ‘’ 报错invalid syntax (, line 15)
最后一行 在 Python 里,f-string 要求将表达式直接嵌入字符串中,并且字符串需要使用引号(单引号 '、双引号 " 或者三引号 '''、""")包裹,同时 f 要紧跟在引号之前,不能有空格。你代码里 f 和单引号之间有空格,这就破坏了 f-string 的正确语法。
去掉 f 和引号之间的空格,让 f 紧挨着引号
多了个空格。我找好久才找到原因解决的
想问下有大佬实现通过函数库将问题回答自动生成word并提供下载的功能吗
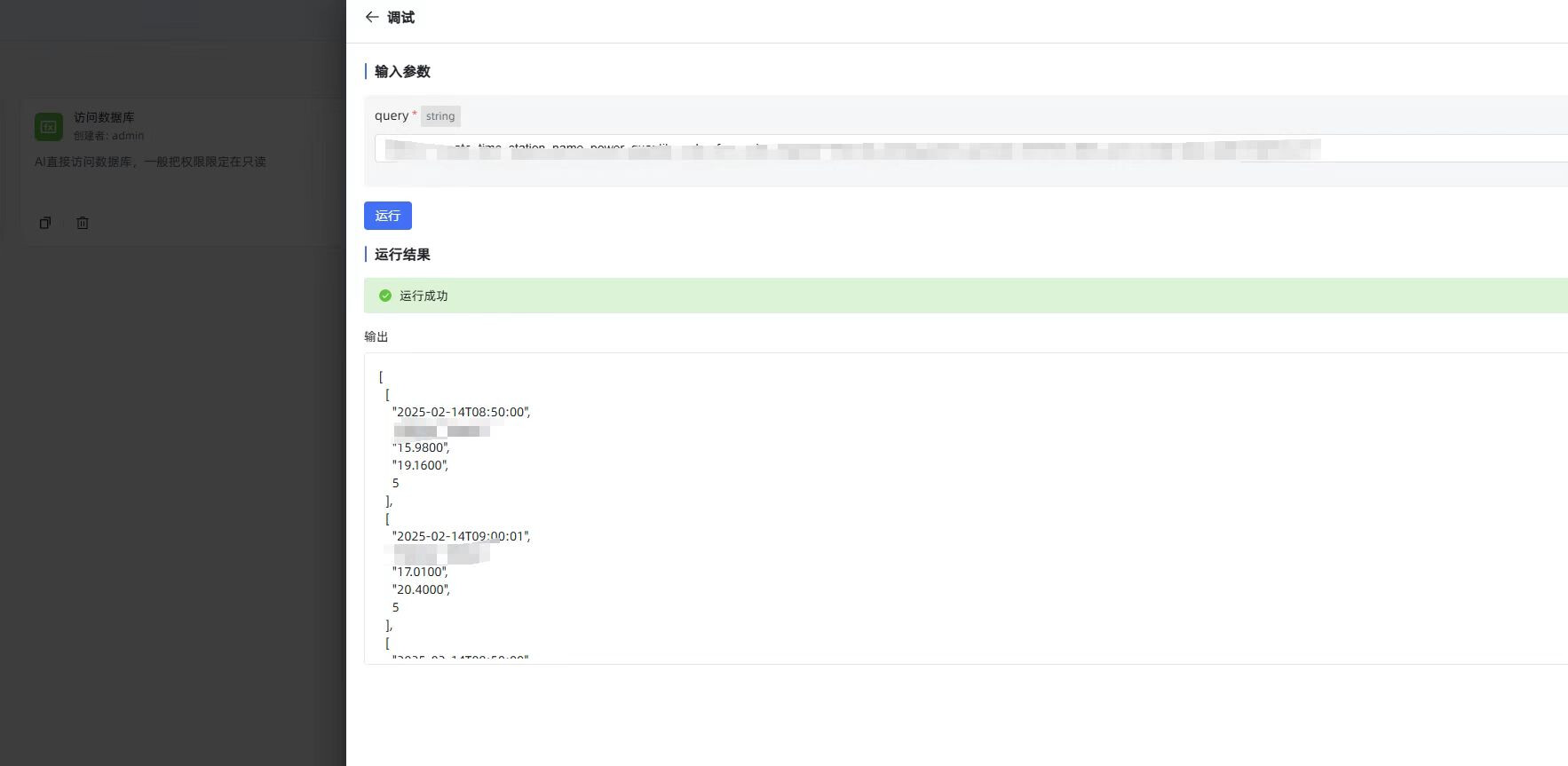
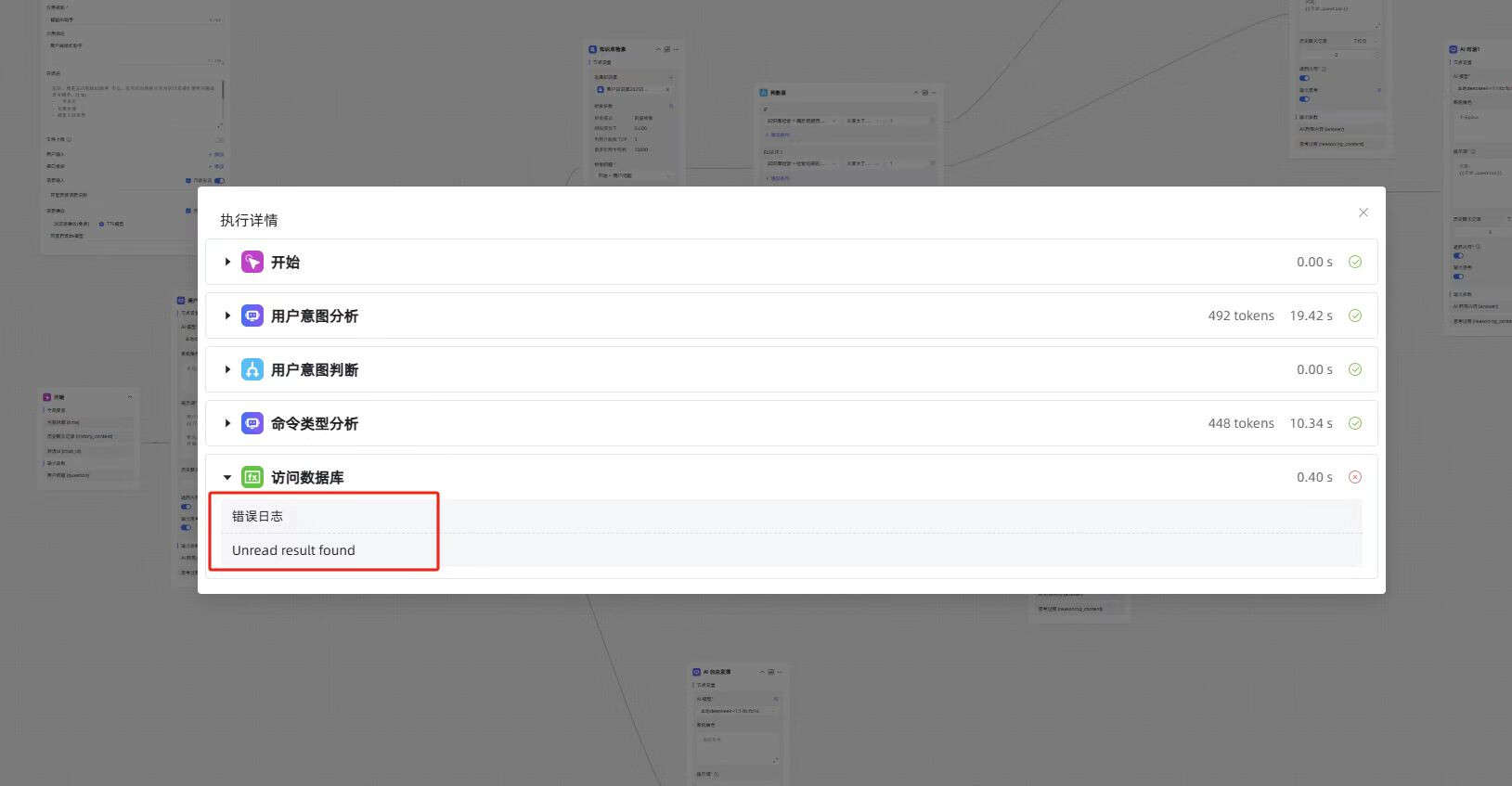
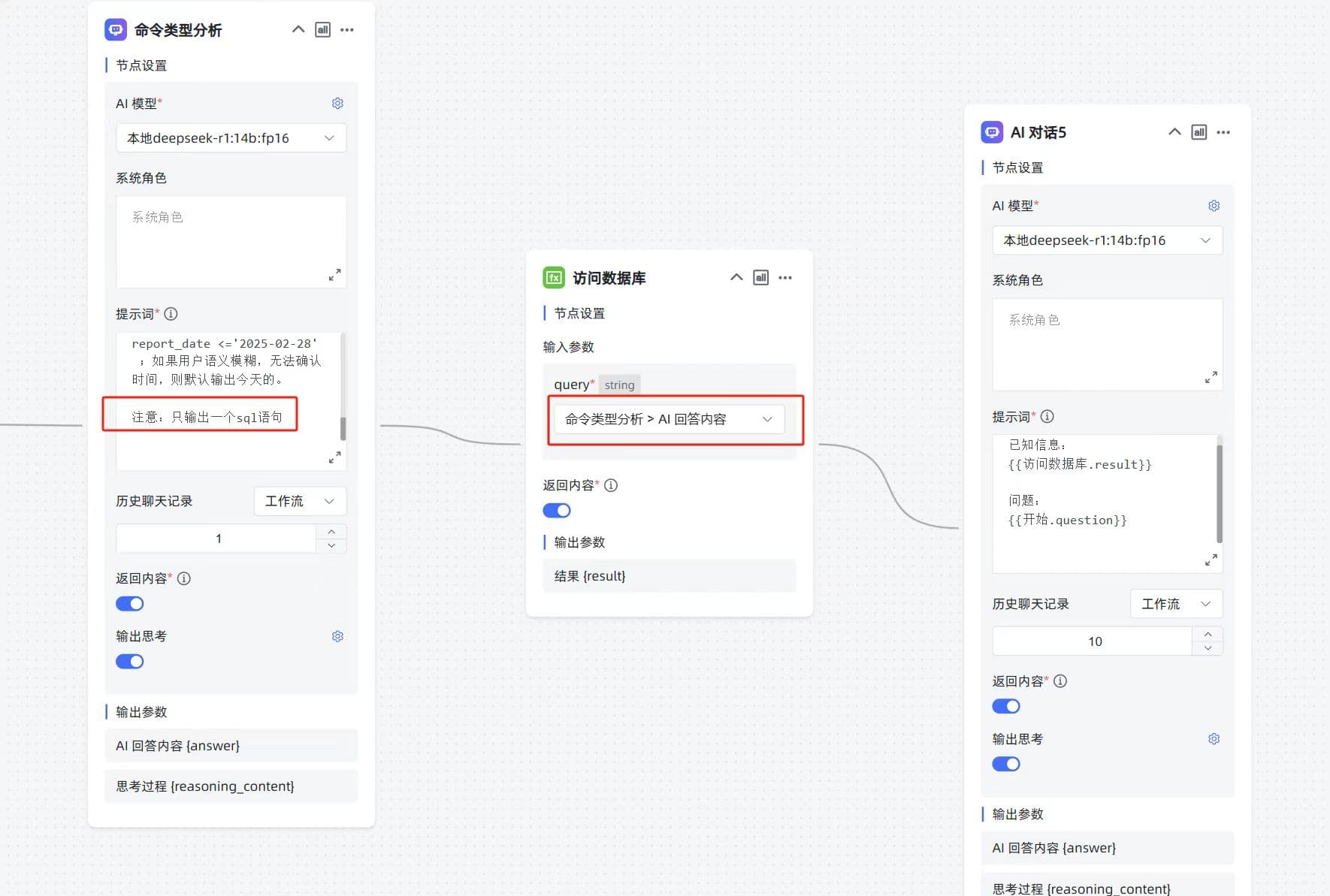
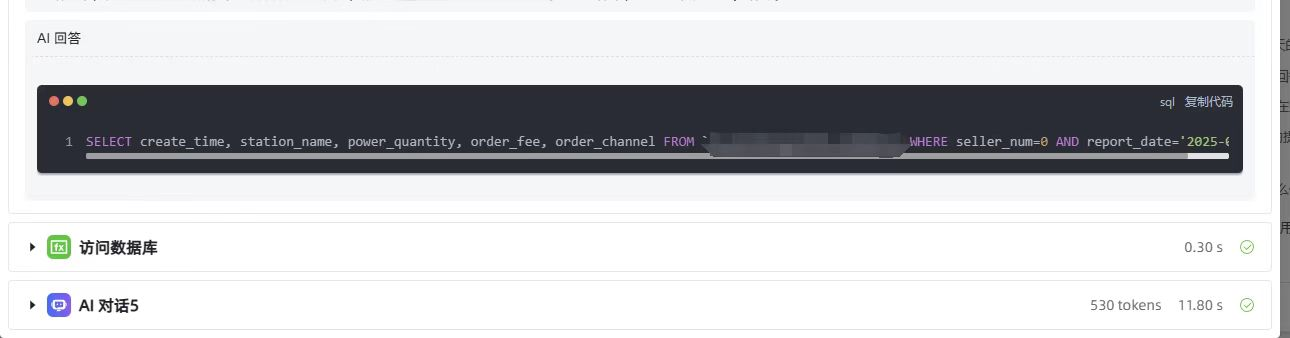
函数库页面直接调试输入 sql 可以正常返回内容。
主要原因在于函数库脚本,执行 SELECT 查询后未调用 fetchall() 获取全部数据,优化函数库如下:
import mysql.connector
from mysql.connector import Error
def execute_sql_query(query, params=None):
"""
执行给定的 SQL 查询,并返回查询结果。
:param query: 要执行的 SQL 查询语句
:param params: SQL 参数,默认为 None
:return: 如果是 SELECT 查询,返回所有查询结果;否则返回受影响的行数;出现错误时返回 None
"""
try:
with mysql.connector.connect(
host="192.168.0.1",
user="root",
passwd="123456",
database="maxkb"
) as connection:
if not connection.is_connected():
print("数据库连接失败!")
return None
# 使用 buffered=True,确保查询结果被全部缓冲
with connection.cursor(buffered=True) as cursor:
cursor.execute(query, params or ())
if query.strip().upper().startswith("SELECT"):
result = cursor.fetchall()
else:
connection.commit() # 提交更改
result = cursor.rowcount
return result
except Error as e:
print(f"Error while connecting to MySQL: {e}")
return None
利用讯飞大模型智能 PPT 生成接口实现,具体参见:讯飞开放平台智能PPT生成 智能PPT生成-PPT生成API-PPT生成-讯飞开放平台
#二、新增函数
# -*- coding:utf-8 -*-
import hashlib
import hmac
import base64
import json
import time
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
class AIPPT():
def __init__(self, APPId, APISecret, Text, templateId):
self.APPid = APPId
self.APISecret = APISecret
self.text = Text
self.header = {}
self.templateId = templateId
# 获取签名
def get_signature(self, ts):
try:
# 对app_id和时间戳进行MD5加密
auth = self.md5(self.APPid + str(ts))
# 使用HMAC-SHA1算法对加密后的字符串进行加密
return self.hmac_sha1_encrypt(auth, self.APISecret)
except Exception as e:
print(e)
return None
def hmac_sha1_encrypt(self, encrypt_text, encrypt_key):
# 使用HMAC-SHA1算法对文本进行加密,并将结果转换为Base64编码
return base64.b64encode(
hmac.new(encrypt_key.encode('utf-8'), encrypt_text.encode('utf-8'), hashlib.sha1).digest()).decode('utf-8')
def md5(self, text):
# 对文本进行MD5加密,并返回加密后的十六进制字符串
return hashlib.md5(text.encode('utf-8')).hexdigest()
# 创建PPT生成任务
def create_task(self):
url = 'https://zwapi.xfyun.cn/api/ppt/v2/create'
timestamp = int(time.time())
signature = self.get_signature(timestamp)
# body= self.getbody(self.text)
formData = MultipartEncoder(
fields={
# "file": (path, open(path, 'rb'), 'text/plain'), # 如果需要上传文件,可以将文件路径通过path 传入
# "fileUrl":"", #文件地址(file、fileUrl、query必填其一)
# "fileName":"", # 文件名(带文件名后缀;如果传file或者fileUrl,fileName必填)
"query": self.text,
"templateId": "20240718489569D", # 模板的ID,从PPT主题列表查询中获取
"author": "XXXX", # PPT作者名:用户自行选择是否设置作者名
"isCardNote": str(True), # 是否生成PPT演讲备注, True or False
"search": str(False), # 是否联网搜索,True or False
"isFigure": str(True), # 是否自动配图, True or False
"aiImage": "normal"
# ai配图类型: normal、advanced (isFigure为true的话生效); normal-普通配图,20%正文配图;advanced-高级配图,50%正文配图
}
)
print(formData)
headers = {
"appId": self.APPid,
"timestamp": str(timestamp),
"signature": signature,
"Content-Type": formData.content_type
}
self.header = headers
print(headers)
response = requests.request(method="POST", url=url, data=formData, headers=headers).text
print("生成PPT返回结果:", response)
resp = json.loads(response)
if (0 == resp['code']):
return resp['data']['sid']
else:
print('创建PPT任务失败')
return None
# 构建请求body体
def getbody(self, text):
body = {
"query": text,
"templateId": self.templateId # 模板ID举例,具体使用 /template/list 查询
}
return body
# 轮询任务进度,返回完整响应信息
def get_process(self, sid):
# print("sid:" + sid)
if (None != sid):
response = requests.request("GET", url=f"https://zwapi.xfyun.cn/api/ppt/v2/progress?sid={sid}",
headers=self.header).text
print(response)
return response
else:
return None
# 获取PPT,以下载连接形式返回
def get_result(self, task_id):
# 创建PPT生成任务
# task_id = self.create_task()
# PPTurl = ''
# 轮询任务进度
while (True):
response = self.get_process(task_id)
resp = json.loads(response)
pptStatus = resp['data']['pptStatus']
aiImageStatus = resp['data']['aiImageStatus']
cardNoteStatus = resp['data']['cardNoteStatus']
if ('done' == pptStatus and 'done' == aiImageStatus and 'done' == cardNoteStatus):
PPTurl = resp['data']['pptUrl']
break
else:
time.sleep(3)
return PPTurl
def getHeaders(self):
timestamp = int(time.time())
signature = self.get_signature(timestamp)
# body = self.getbody(self.text)
headers = {
"appId": self.APPid,
"timestamp": str(timestamp),
"signature": signature,
"Content-Type": "application/json; charset=utf-8"
}
return headers
def getTheme(self):
url = "https://zwapi.xfyun.cn/api/ppt/v2/template/list"
self.header = self.getHeaders()
body = {
"payType": "not_free",
# "style": "简约", # 支持按照类型查询PPT 模板
# "color": "红色", # 支持按照颜色查询PPT 模板
# "industry": "教育培训", # 支持按照颜色查询PPT 模板
"pageNum": 2,
"pageSize": 10
}
response = requests.request("GET", url=url, headers=self.header).text
print(response)
return response
def createOutline(self):
# if('' ==fileUrl and '' == filePath):
url = "https://zwapi.xfyun.cn/api/ppt/v2/createOutline"
body = {
"query": self.text,
"language": "cn",
"search": str(False), # 是否联网搜索,True or False
}
response = requests.post(url=url, json=body, headers=self.getHeaders()).text
print("生成大纲完成:\n", response)
return response
def createOutlineByDoc(self, fileName, fileUrl=None, filePath=None):
# if('' ==fileUrl and '' == filePath):
url = "https://zwapi.xfyun.cn/api/ppt/v2/createOutlineByDoc"
formData = MultipartEncoder(
fields={
"file": (filePath, open(filePath, 'rb'), 'text/plain'), # 如果需要上传文件,可以将文件路径通过path 传入
"fileUrl": fileUrl, # 文件地址(file、fileUrl必填其一)
"fileName": fileName, # 文件名(带文件名后缀;如果传file或者fileUrl,fileName必填)
"query": self.text,
"language": "cn",
"search": str(False), # 是否联网搜索,True or False
}
)
timestamp = int(time.time())
signature = self.get_signature(timestamp)
headers = {
"appId": self.APPid,
"timestamp": str(timestamp),
"signature": signature,
"Content-Type": formData.content_type
}
self.header = headers
response = requests.post(url=url, data=formData, headers=headers).text
print("生成大纲完成:\n", response)
return response
def createPptByOutline(self, outline):
url = "https://zwapi.xfyun.cn/api/ppt/v2/createPptByOutline"
body = {
"query": self.text,
"outline": outline,
"templateId": self.templateId, # 模板的ID,从PPT主题列表查询中获取
"author": "XXXX", # PPT作者名:用户自行选择是否设置作者名
"isCardNote": True, # 是否生成PPT演讲备注, True or False
"search": False, # 是否联网搜索,True or False
"isFigure": True, # 是否自动配图, True or False
"aiImage": "normal",
# ai配图类型: normal、advanced (isFigure为true的话生效); normal-普通配图,20%正文配图;advanced-高级配图,50%正文配图
}
print(body)
response = requests.post(url, json=body, headers=self.getHeaders()).text
print("创建生成任务成功:\n", response)
resp = json.loads(response)
if (0 == resp['code']):
return resp['data']['sid']
else:
print('创建PPT任务失败')
return None
def generate_ppt(count):
# 控制台获取
APPId = "*****"
APISecret = "************"
# 查询PPT主题列表
# demo1 = AIPPT(APPId,APISecret,'','')
# templateId = demo1.getTheme() # 获取模板列表
# print("支持模板列表:\n",templateId)
templateId = "20240718489569D" # 该模板ID,需要通过getTheme() 方法获取模板列表,然后从中挑选
# 流程一:根据描述或者文档直接生成PPT;(流程一、流程二代码不能同时打开)
# # 流程一开始
Text = count
demo = AIPPT(APPId, APISecret, Text, templateId)
taskid = demo.create_task()
# # 流程一结束
# 流程二: 先生成大纲(支持上传文本),再通过大纲生成PPT;(流程一、流程二代码不能同时打开)
# # 流程二开始
# title = "秋分时节的农业管理策略" #设定大纲主题
# filename = "test.pdf" # 需要根据文档上传时,请填写文档路径;要求:字数不得超过8000字,文件限制10M。上传文件支持pdf(不支持扫描件)、doc、docx、txt、md格式的文件。
# filePath = "data/test.pdf" # 文件路径,也可以通过fileurl 字段上传对象存储地址,具体见方法:createOutlineByDoc
# demo = AIPPT(APPId, APISecret, title, templateId)
# res = demo.createOutlineByDoc(fileName=filename,filePath=filePath)
# data = json.loads(res)
# outline = data["data"]["outline"]
# taskid = demo.createPptByOutline(outline)
# # 流程二结束
result = demo.get_result(taskid)
print("生成的PPT请从此地址获取:\n" + result)
return result
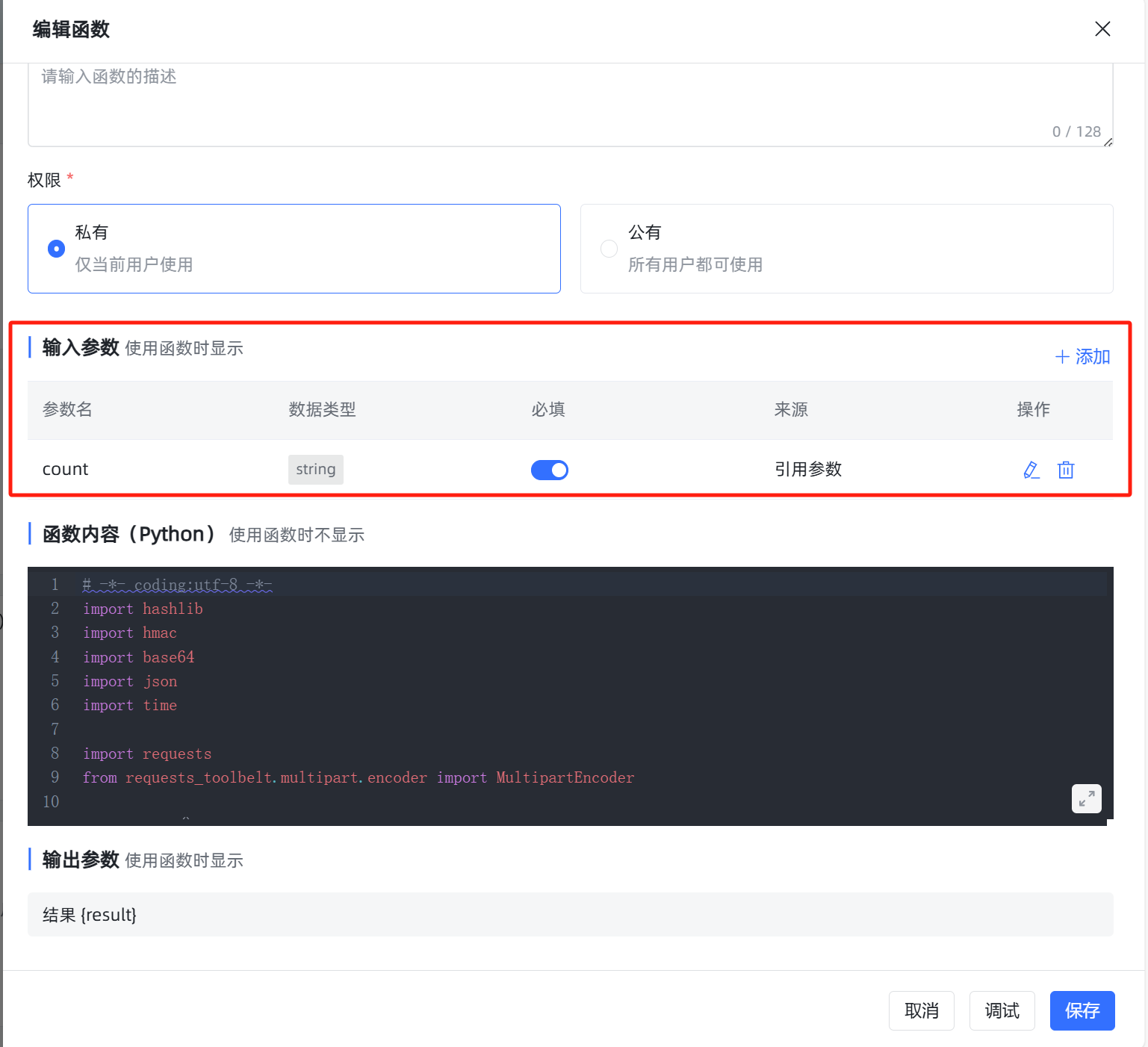
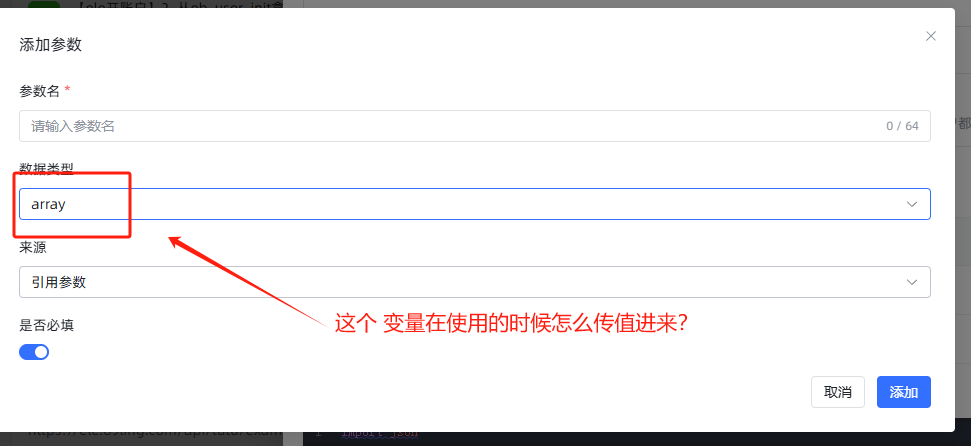
如下图所示添加 count 参数:
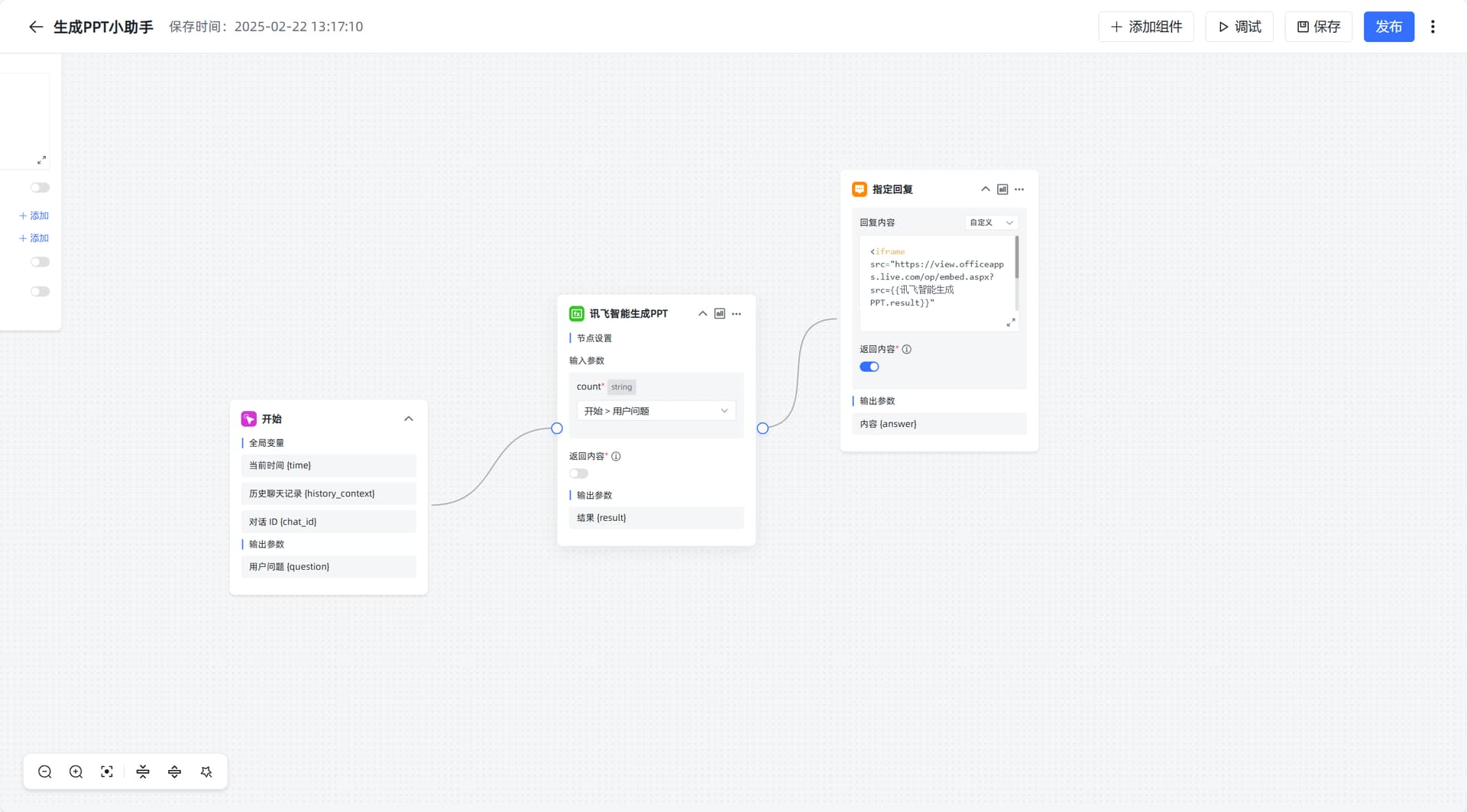
使用 MaxKB 中的高级编排,其中工作流编排流程如下所示:
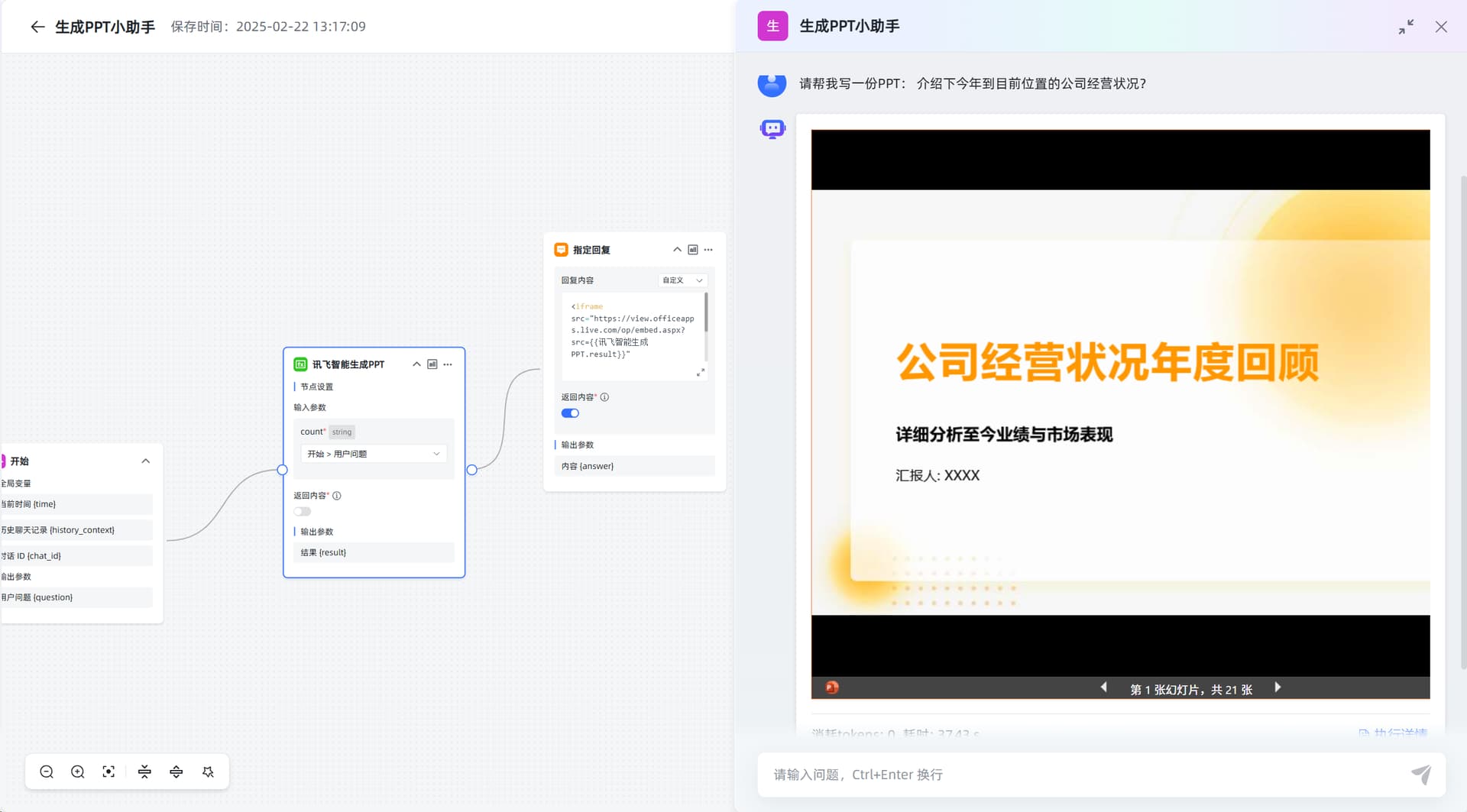
其中指定回复使用 Office Online Viewer 展示 PPT。
<iframe src="https://view.officeapps.live.com/op/embed.aspx?src={{讯飞智能生成PPT.result}}"
width="800" height="600" frameborder="0">
</iframe>
为啥我把f和引号之间的空格去掉直接全部报错了
请问这个鉴权函数,能改成获取我们内部OA权限的方式吗?是只用改接口然后获取返回内容就可以了吗?我的想法是通过获取我们内部OA的一个返回结果,通过结果走一个判断器导向不同的知识库查询。