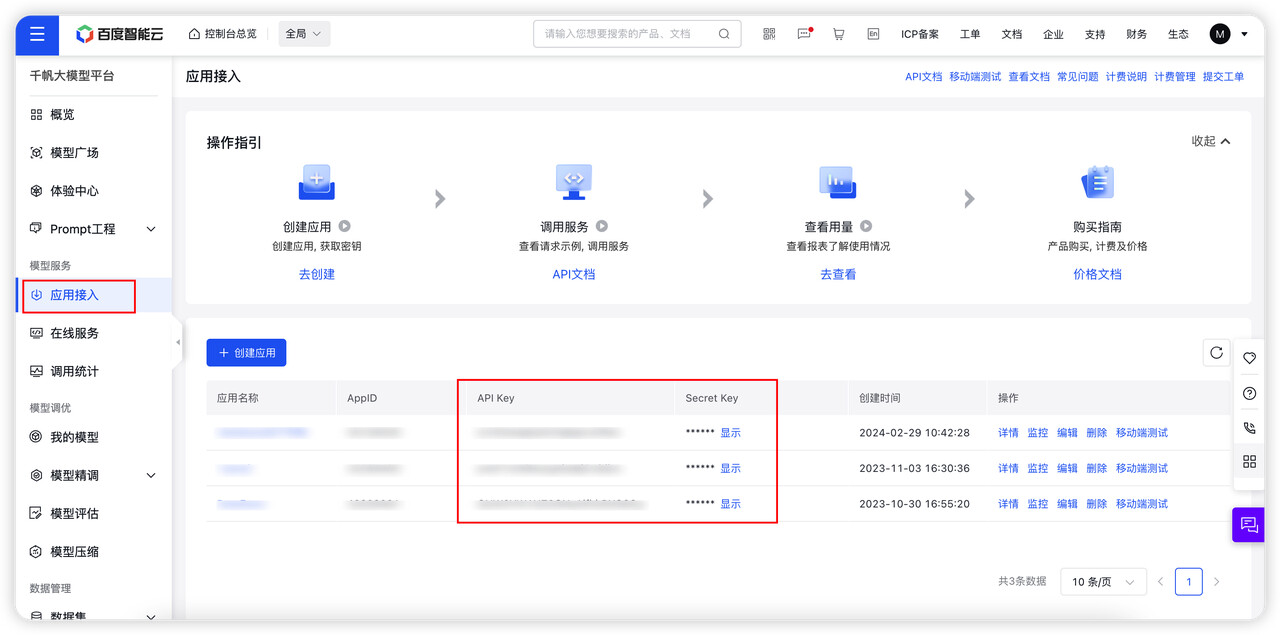
百度千帆模型需要先去千帆大模型中创建应用,接入应用的 API Key
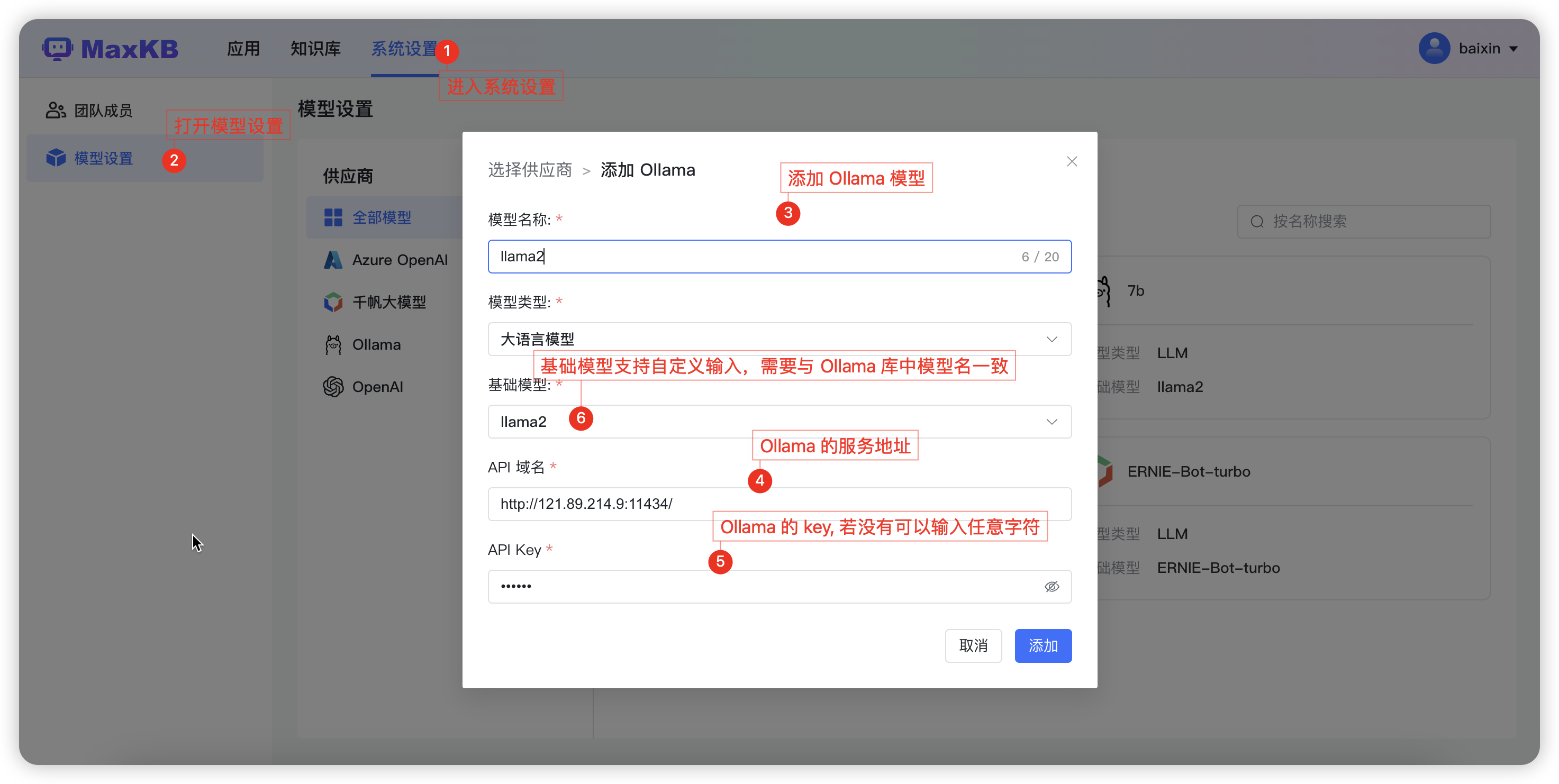
Ollama 模型接入(需检查一下Ollama 服务端口是否允许访问):
按照操作手册还是接入不了,需要发一下报错信息。
现在千帆的可以添加进去了,ollama还是不行
百度千帆按照操作填入key和secret之后,接口返回500,ollama一直提示域名格式不正确,我用的windows环境 docker,难道和环境有关系吗?
试试在API域名端口号后加/v1
例如:
https://您ollama所在服务的ip地址:您ollama的端口号/v1
可以我跑服务器自己的大模型嘛?
应该怎么操作呀
请问可以更改该向量模型吗?加载本地的,我看默认用的是text2vec-base-chinese这个,可以换其他的吗,可以的话,直接本地路径可以吗?
可以的
1 在启动容器的时候,通过-v 将宿主机模型挂载到容器内部
2 修改容器中/opt/maxkb/conf/config.yaml 配置文件 指定向量化模型为挂载目录
先安装ollama 使用ollama对接私有模型 然后再maxkb添加ollama供应商模型
我不是用docker部署到本地的,要怎么修改向量模型路径呢?
配置文件
EMBEDDING_MODEL_NAME: /opt/maxkb/model/shibing624_text2vec-base-chinese
指定你本地模型绝对路径
如果配置绝对路径就是使用本地已有模型 如果配置名称 则是从huggingface上下载到本地 并使用
向量模型的格式有要求吗?直接从魔搭上下载的可以不?
在 huggingface上下载
不知道为啥一直从线上加载,明明已经在配置文件里指定路径啦
“EMBEDDING_MODEL_PATH”: “/opt/maxkb/model/embedding/shibing624_text2vec-base-chinese”
一直报这个错误WARNING:sentence_transformers.SentenceTransformer:No sentence-transformers model found with name sentence-transformers/shibing624_text2vec-base-chinese. Creating a new one with MEAN pooling.
EMBEDDING_MODEL_NAME: 模型名称 如果是 绝对路径 则加载本地模型 如果只是 模型名称则从huggingface上下载
EMBEDDING_MODEL_PATH: 如果EMBEDDING_MODEL_NAME传的是模型名称EMBEDDING_MODEL_PATH则是指定模型下载目录
EMBEDDING_MODEL_PATH: /opt/maxkb/model/embedding
EMBEDDING_MODEL_NAME: /opt/maxkb/model/embedding/shibing624_text2vec-base-chinese
如果EMBEDDING_MODEL_NAME使用的是绝对路径EMBEDDING_MODEL_PATH则无效
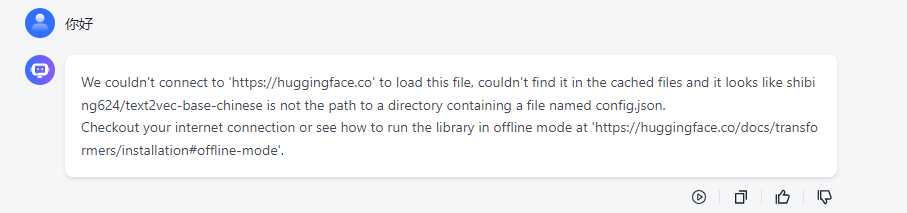
Can’t load tokenizer for ‘gpt2’. If you were trying to load it from ‘https://huggingface.co/models’, make sure you don’t have a local directory with the same name. Otherwise, make sure ‘gpt2’ is the correct path to a directory containing all relevant files for a GPT2TokenizerFast tokenizer.
为什么会调用gpt2呢?
像阿里云的2h2g 40盘怎么部署该应用呢,服务器是90多包年的没钱买贵的