EMBEDDING_MODEL_PATH: /opt/maxkb/model/embedding
EMBEDDING_MODEL_NAME: /opt/maxkb/model/embedding/shibing624_text2vec-base-chinese
如果EMBEDDING_MODEL_NAME使用的是绝对路径EMBEDDING_MODEL_PATH则无效
Can’t load tokenizer for ‘gpt2’. If you were trying to load it from ‘https://huggingface.co/models’, make sure you don’t have a local directory with the same name. Otherwise, make sure ‘gpt2’ is the correct path to a directory containing all relevant files for a GPT2TokenizerFast tokenizer.
为什么会调用gpt2呢?
1 个赞
像阿里云的2h2g 40盘怎么部署该应用呢,服务器是90多包年的没钱买贵的
可以的,已安排在下个版本的计划中。
GPT2是为了计算对话tokens
知识库中的分段内容在存储在数据库, 没有存储原始文档。
是的,因为演示的公开访问链接是用户端提问的界面,知识来源放到管理端是考虑到给维护人要调试知识库用,担心知识库的内容若不规范放给用户看怕有误导所以未显示知识来源。
后期看大家需求再定要不要加个设置让用户端显示知识来源。
现在还不支持。
应用的对话日志详情中可以看到用户端的知识来源
想问下这里可以修改吗?
安装docker 然后通过官网命令运行maxkb
感谢指导
实测bge-large-zh-v1.5嵌入模型效果很好 建议后续版本考虑采用
传个模型文件不难 但maxkb内部的config.yaml死活映射不到宿主机内 现在是手动进入容器内更新config文件 这样的话每次更新maxkb镜像都需要手改config。。。。
只要尝试映射容器的/opt/maxkb下的目录 就会出各种错
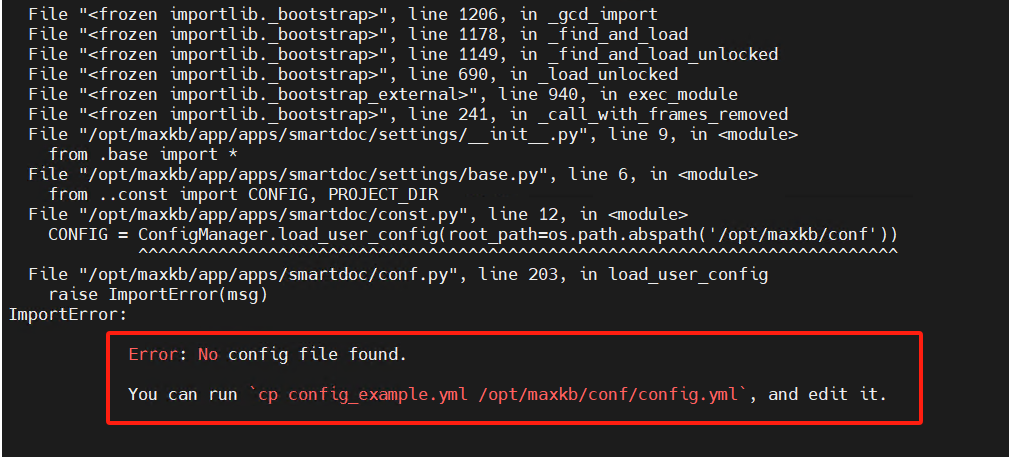
可以使用-v 将配置文件目录挂载到宿主机
怎么使用ollama添加自己训练过的私有模型
商用授权怎么获取,费用是多少
Mac本地运行这个maxkb呢,我在github上拉取了代码,然后poetry install 了,再运行python mian.py start 还是会出问题,有个关键性的问题就是,我mac本地/opt里面没有maxkb 我需要mkdir 然后再mkdir conf 再cp yml文件再运行的话 就会出现以下问题:

能不能考虑出一个个人专业版,这2万/套也太贵了点,另外,向量模型就不能优化一下么,感觉有点难在本地部署
请问下高级编排也出现了这个报错,下载好gpt2模型后,需要在哪一块设置地址呢?我是本地离线部署ollama千问2.5和maxkb的。
1 个赞
模型对接可以参考官网教程。
那请问你要怎么解决哇?