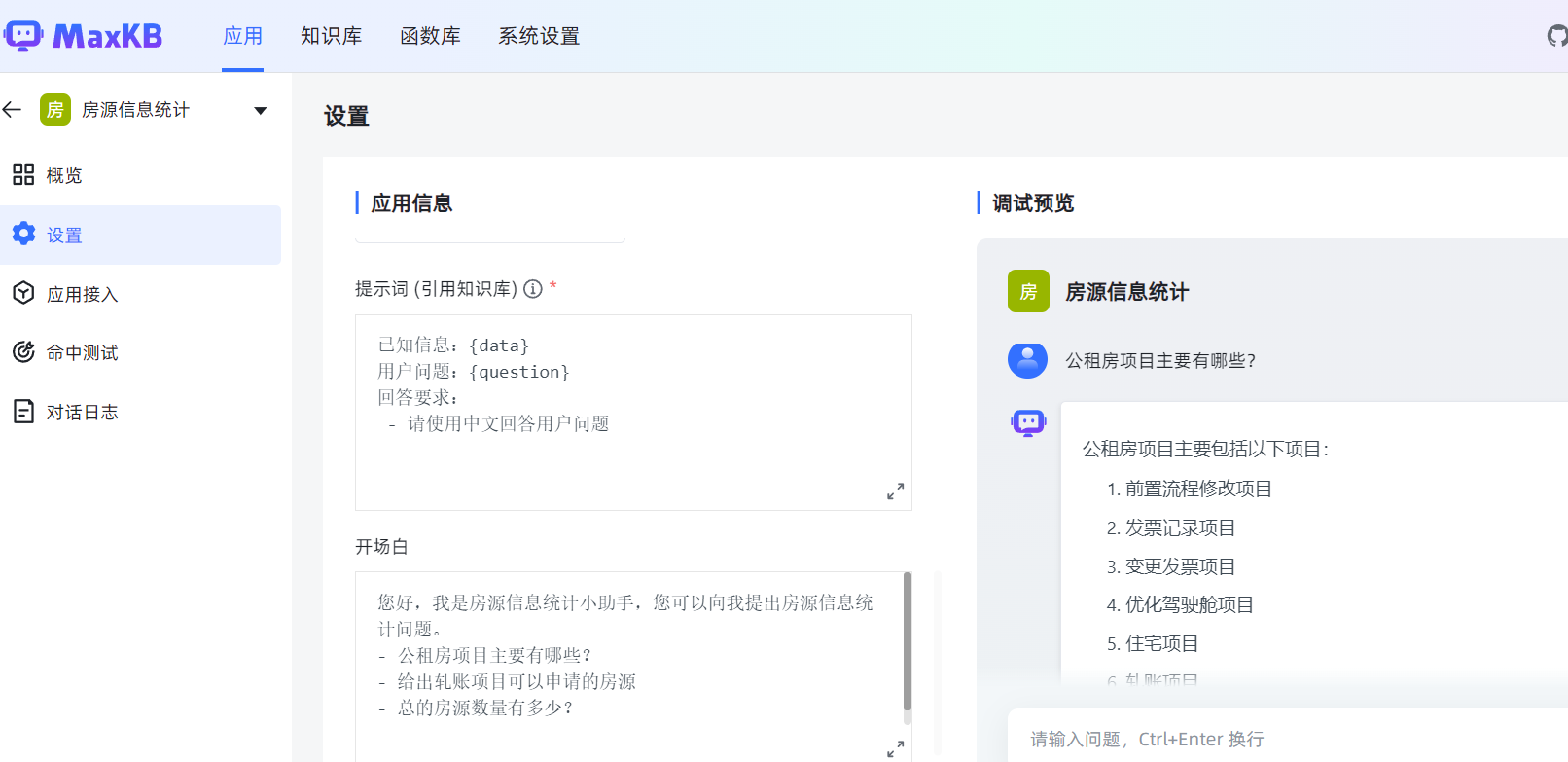
问题描述:
导入markdown文档,若文档中存在代码段,且代码中的注释为“#”,会导致智能分段失效。
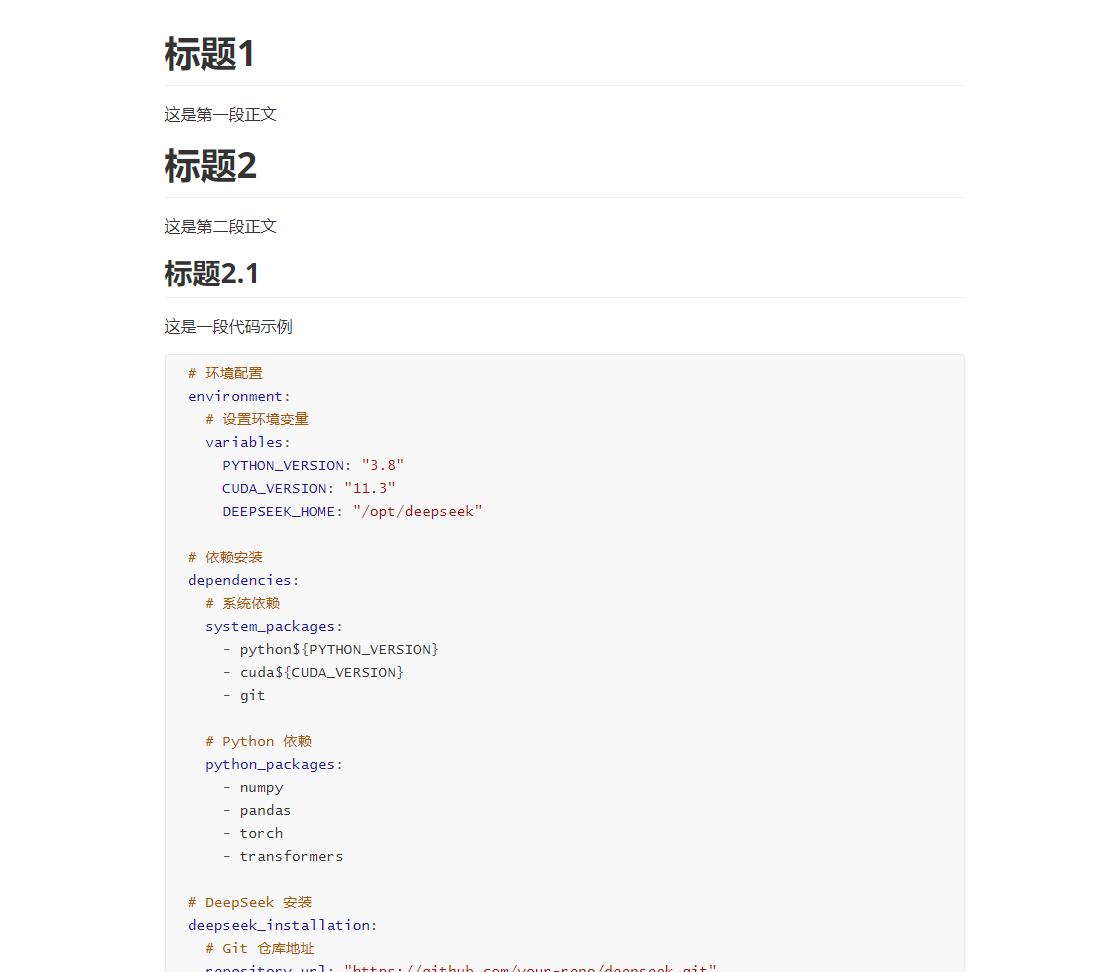
尝试过使用正则表达式解决代码段问题,但又无法同时按照标题级别切分了。
解决方案及效果:
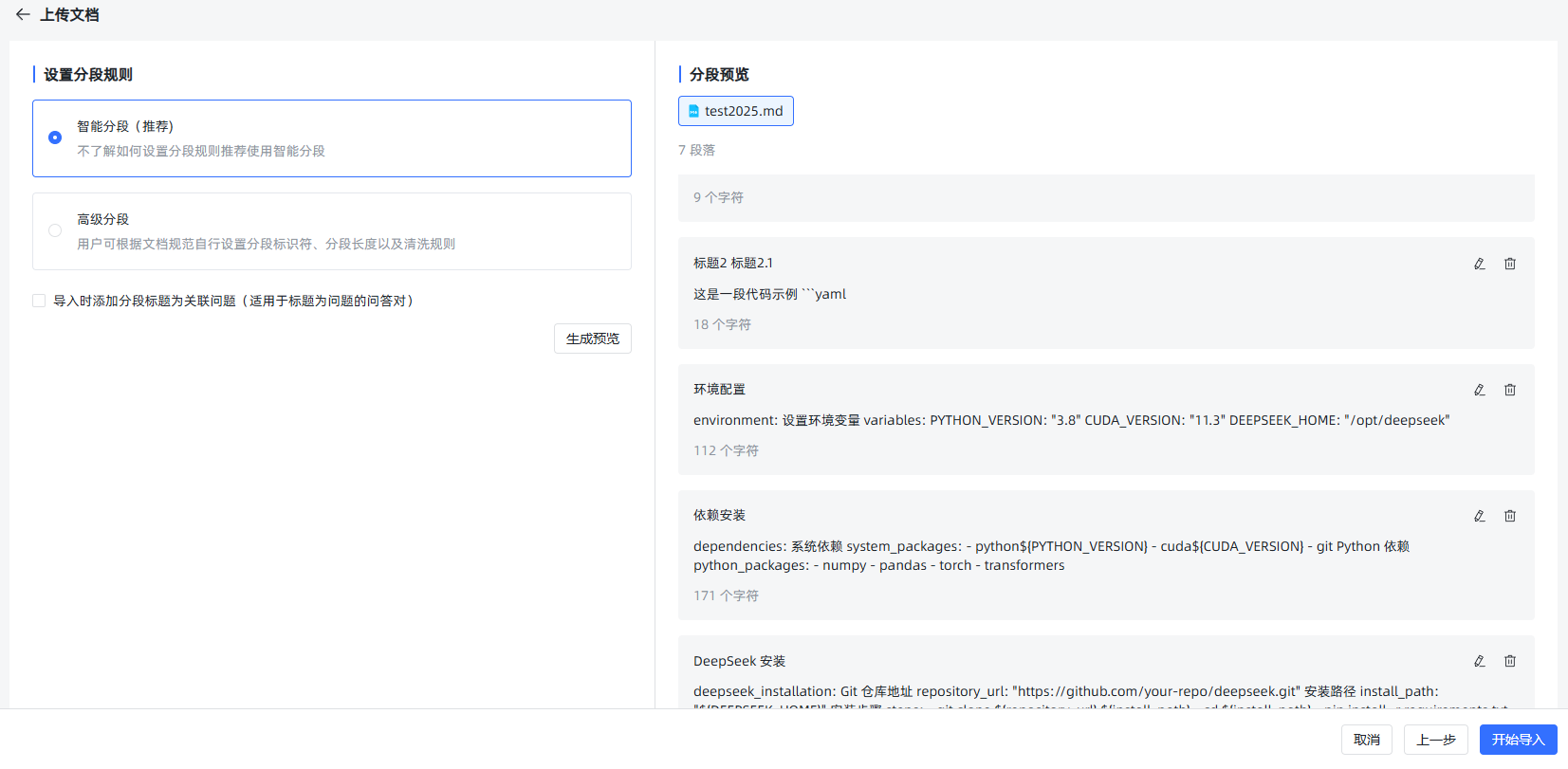
能完全自动识别代码片段,且无需改变缩进、注释。
问题描述:
导入markdown文档,若文档中存在代码段,且代码中的注释为“#”,会导致智能分段失效。
尝试过使用正则表达式解决代码段问题,但又无法同时按照标题级别切分了。
解决方案及效果:
能完全自动识别代码片段,且无需改变缩进、注释。
1、问题描述:excel 中如果内嵌了图片 Qa问答对 分段的时候会出BUG 字符数为0
2、期待方案:自动识别图片到分段中 用于显示
再补充一个问题:一个Word类型的操作手册,怎么切分能保证模型能识别出正确的操作顺序?目前智能分段也不做overlap,怎么保证批量导入很多文件时操作步骤不乱?总不能靠人一个个去改吧,工作量也太大了。
PDF文件上传MaxKB后分段错乱问题如何解决
能否贴个例子,看看针对excel,word里是如何描述说明的
导入一份个人信息表,按行分段,完全命中不了。。。
导入大于1m的文档,预览转圈圈加载后,不显示,点击开始导入,显示提交成功,但是文件列表没看到新增文件
问题:通过Excel问答对上传问题,部分sheet中的问题无法关联
答案:一定要按照excel模版的列名称命名,不得调整列名称,系统是按照列名称核对的
使用word文档构建知识库,我尝试采用word中的样式1、样式2、正文进行格式化,无法智能分段。如果做,才能让系统自动识别分段?
能否给个具体实现的操作截图了,文字描述的话,很难理解。还有相关直播介绍需要通过什么方式关注呢?
知识库文章上传,如果需要分段有标题,除了excel还有其他格式的模版?
excel的分段长度有4k的限制。
Markdown 可以定义分段标题吗?是否有模版可以参考?
maxkb知识库当命中方式为直接回答时,只能返回一个分段内容,能返回所有符合条件的分段内容吗
?
可以在提示词加入回答要求:
说的太对了,而且老是按设好的长度来切,很容易乱
问题描述:当二级标题中文数字编号超过10时,使用论坛的正则表达式无法分段[十一、十二、十三…]。

解决方案及效果:
解决方案:改进正则表达式为如下
[零一二三四五六七八九十百千万][、][ \u4e00-\u9fa5a-zA-Z]+
正则表达式解释:
[零一二三四五六七八九十百千万亿]+:匹配一个或多个中文数字字符(包括零、一、二、三、四、五、六、七、八、九、十、百、千、万、亿等)。、:匹配顿号“、”。最后再给出最近试用出比较常用的正则表达式,可适用于公司内部规章制度等结构清晰的文档等。
![]() ([一二三四五六七八九十百]+、)(.*?)
([一二三四五六七八九十百]+、)(.*?)
![]() 第(?:(?:一|二|三|四|五|六|七|八|九|十)+|\d+)章[ \u4e00-\u9fa5a-zA-Z]+
第(?:(?:一|二|三|四|五|六|七|八|九|十)+|\d+)章[ \u4e00-\u9fa5a-zA-Z]+
![]() 第(?:(?:一|二|三|四|五|六|七|八|九|十)+|\d+)条
第(?:(?:一|二|三|四|五|六|七|八|九|十)+|\d+)条
![]() 另外,可用”#“在原文档中的每个一级、二级、三级标题前做标记,一级标题则”#+空格“,二级标题前则”##+空格“。然后导入文档直接可用智能分段达到上述使用正则表达式的效果。
另外,可用”#“在原文档中的每个一级、二级、三级标题前做标记,一级标题则”#+空格“,二级标题前则”##+空格“。然后导入文档直接可用智能分段达到上述使用正则表达式的效果。
maxkb可以参考其他平台增加个分段重叠长度,保留分段之间的语义关系。现在的文档分段太拉胯了,导致找回命中率极低