方案一:不同用户角色人员检索同一个知识库进行智能问答
a、实现原理
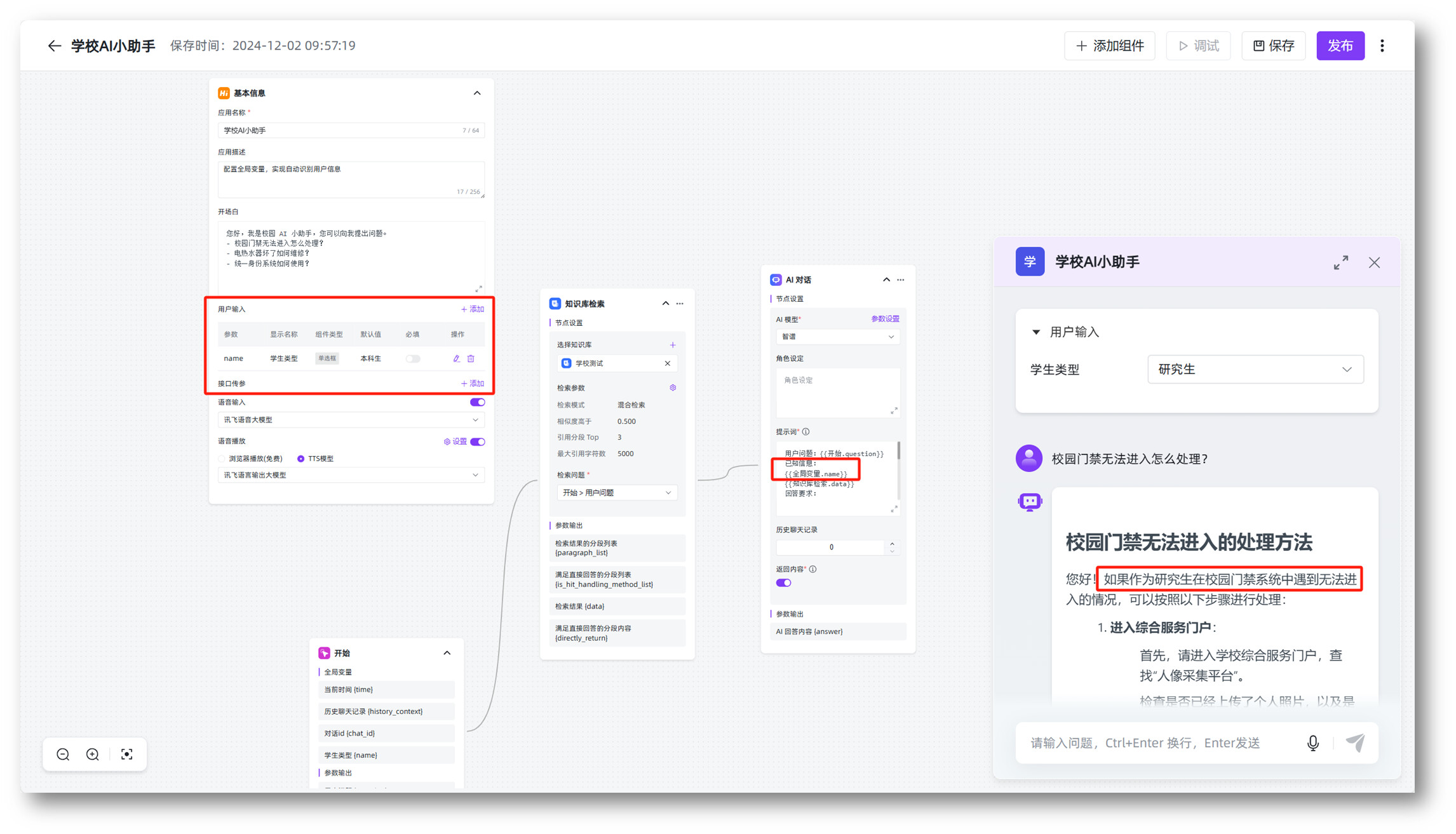
在全局参数传值的时候,直接传值用户身份,将用户角色信息作为提示词扔给大模型,让大模型根据不同角色输出不同内容。
b、优缺点
只需维护一个知识库即可,针对特别场景内容,例如同一个知识库下不同人员看到不同数据的场景比较合适。缺点是对大模型依赖较高,如果大模型判断不准确,回复也会不准确。
方案二:不同用户角色人员检索不同知识库进行智能问答
a、实现原理
在全局参数传值的时候,直接传值用户身份,通过判断器判断用户的角色,指向对应的知识库进行问题结果检索。
编排流程图如下:
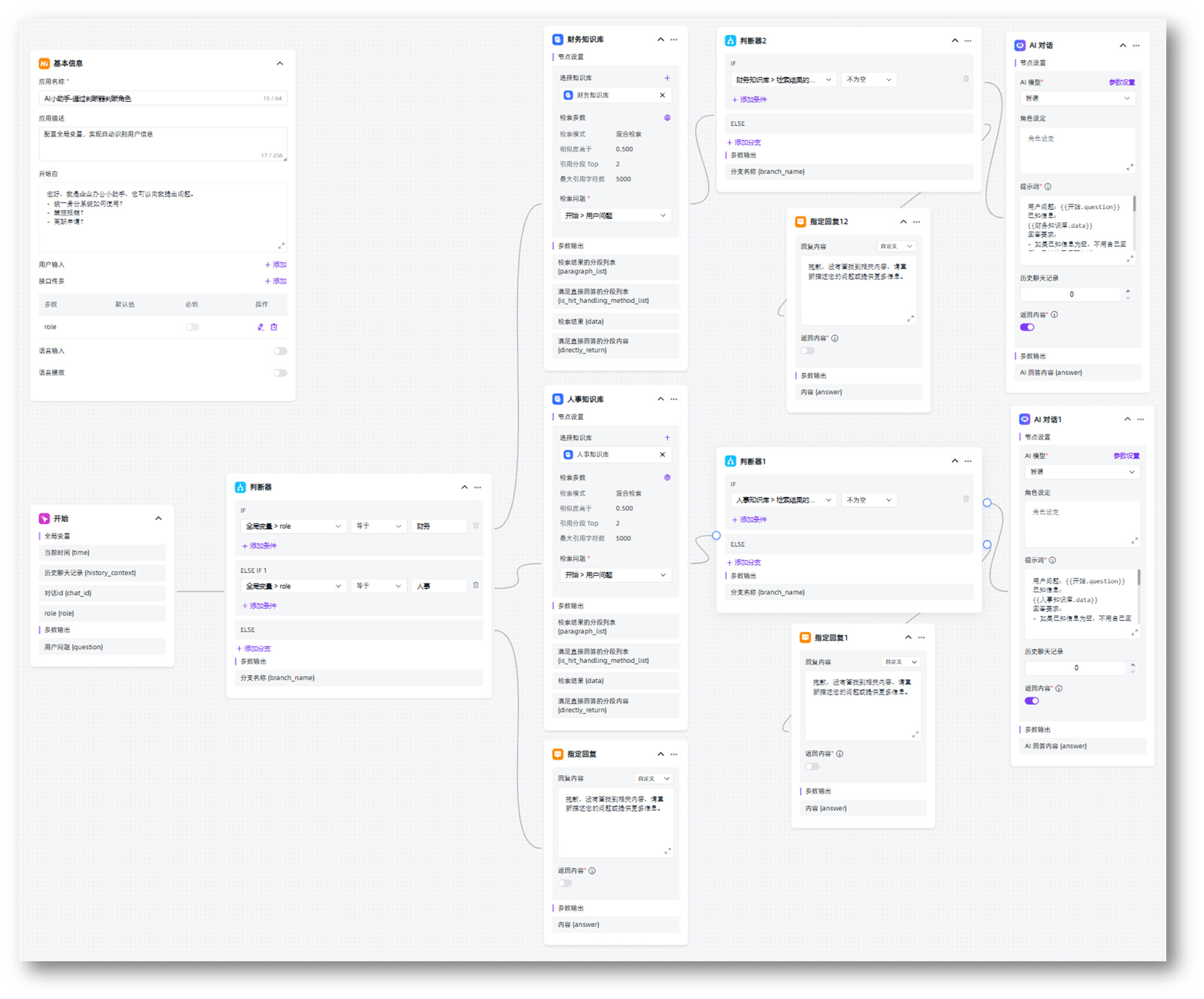
实现效果:如果角色是人事,匹配到人事知识库进行回复,如果角色为空,应用回复指定内容,可以避免用户非任何角色下随意使用应用去提问。


b、优缺点
确保精准匹配到对应的知识库进行检索及回答,回答准确率有保证,同时人员权限完全隔离。缺点是需要维护多个知识库,编排流程相对复杂。
方案三:不同用户看到不同应用,使用不同的应用进行智能问答**
a、实现原理
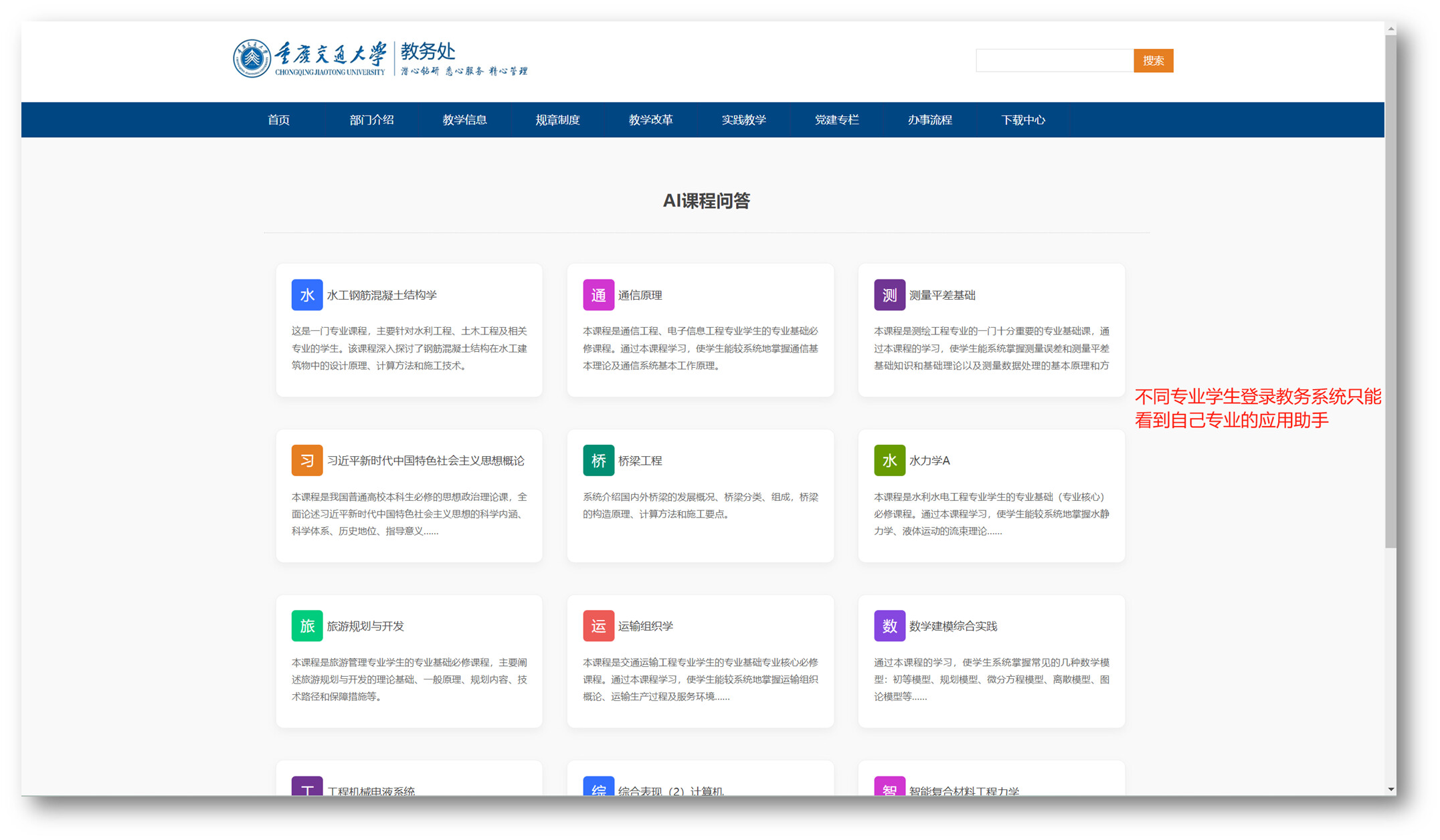
MaxKB 创建多个应用,在嵌入系统的项目终端用JS前端做控制,不在 MaxKB 上做任何参数化,前端根据不同用户角色调用不同的 MaxKB 应用,以实现权限划分。
例如学校这种场景,不同专业学生登录教务系统只能看到自己专业的应用助手:
b、优缺点
MaxKB 不需要做任何配置,依靠嵌入源系统的前端页面菜单权限来控制。缺点是不同应用对外暴露的 URL 如果被用户获取,同样可以对其他知识库进行问答。
总结
目前 MaxKB 可以实现以上三种权限隔离,第一种是实现数据级的权限划分、第二种是实现知识库级的权限划分、第三种是实现应用级的权限划分。 总体来看目前第二种方案 对回复的准确度和权限隔离效果会更好。