一、从hugging face下载模型
向量模型下载地址(需科学上网):https://huggingface.co/models
网盘下载地址:models–moka-ai–m3e-base.zip。链接: 百度网盘 请输入提取码 提取码: raey
huggingface 镜像站(推荐): Models - Hugging Face
以下几种方式均需要提前按照好python和pip
方法一:通过代码下载
1、需要先安装 sentence-transformers
# pythonm3e 和 text2vec 都可以直接通过 sentence-transformers 直接使用,其他向量模型请参考官方文档
# 安装sentence-transformers
pip install -U sentence-transformers
# 安装成功后使用pip list 检查numpy版本是否小于2.0.0,如果大于2.0.0版本,请降级
pip install numpy==1.26.42
2、安装完成后,可以使用以下代码来使用 M3E Models
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
3、执行脚本,下载模型
python model_download.py
# 下载到默认路径 ~/.cache/huggingface/hub
方法二:使用huggingface-cli工具下载
huggingface-cli 是 Hugging Face 官方提供的命令行工具,自带完善的下载功能。
1、安装依赖
# 注意:huggingface_hub 依赖于 Python>=3.8
pip install -U huggingface_hub
2、设置环境变量
# Linux
export HF_ENDPOINT=https://hf-mirror.com
# Windows
$env:HF_ENDPOINT = "https://hf-mirror.com"
3、下载模型
# huggingface_hub v0.23.0 已弃用 --resume-download参数,现在默认断点续传
huggingface-cli download moka-ai/m3e-large --local-dir m3e-large
方法三:使用脚本下载
项目访问地址:https://github.com/LetheSec/HuggingFace-Download-Accelerator,利用 HuggingFace 官方的下载工具 huggingface-cli 和 hf_transfer 从 HuggingFace 镜像站上对模型和数据集进行高速下载。该脚本只是对 huggingface-cli 的一个简单封装。
1、下载脚本
git clone https://github.com/LetheSec/HuggingFace-Download-Accelerator.git
2、下载模型
python hf_download.py --model moka-ai/m3e-base --save_dir m3e-base
二、在MaxKB只能够配置模型
1、拷贝MaxKB的默认模型
# 将容器中模型拷贝到宿主机上
cd /opt/maxkb
docker cp maxkb:/opt/maxkb/model .
# 如果误操作导致容器内部model文件下没有默认模型,可以启动一个新的容器进行拷贝
# docker run -d --name=maxkb_new 1panel/maxkb-pro:v1.5.1
# docker cp maxkb_new:/opt/maxkb/model .
2、修改docker-compose.yaml
注意:模型向量模型路径为:${MAXKB_BASE}/maxkb/model:/opt/maxkb/model
version: "2.1"
services:
maxkb:
container_name: maxkb
hostname: maxkb
restart: always
image: ${MAXKB_IMAGE_REPOSITORY}/maxkb-pro:${MAXKB_VERSION}
ports:
- "${MAXKB_PORT}:8080"
healthcheck:
test: ["CMD", "curl", "-f", "localhost:8080"]
interval: 10s
timeout: 10s
retries: 120
volumes:
- /tmp:/tmp
- ${MAXKB_BASE}/maxkb/logs:/opt/maxkb/app/data/logs
- ${MAXKB_BASE}/maxkb/python-packages:/opt/maxkb/app/sandbox/python-packages
- ${MAXKB_BASE}/maxkb/model:/opt/maxkb/model
env_file:
- ${MAXKB_BASE}/maxkb/conf/maxkb.env
depends_on:
pgsql:
condition: service_healthy
networks:
- maxkb-network
entrypoint: ['bash','-c']
command: ['rm -f /opt/maxkb/app/tmp/*.pid & python /opt/maxkb/app/main.py start']
networks:
maxkb-network:
driver: bridge
ipam:
driver: default
3、启动maxkb服务
## 添加完之后重新启动
cd /opt/maxkb
docker-compose -f docker-compose.yml -f docker-compose-pgsql.yml up -d
## 检查状态
mkctl status
4、拷贝新下载的向量模型放在model文件下
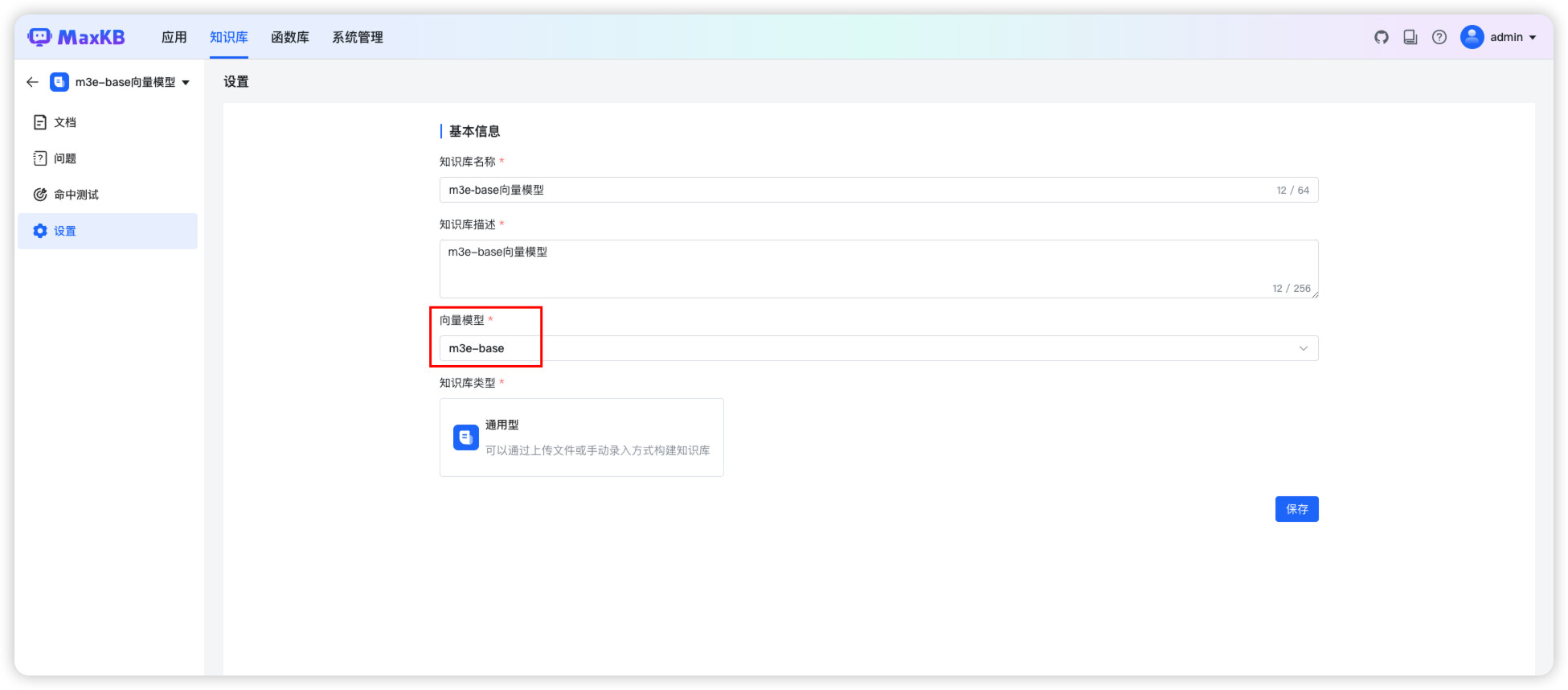
三、在MaxKB 界面中配置向量模型
1、在系统设置中添加本地向量模型。
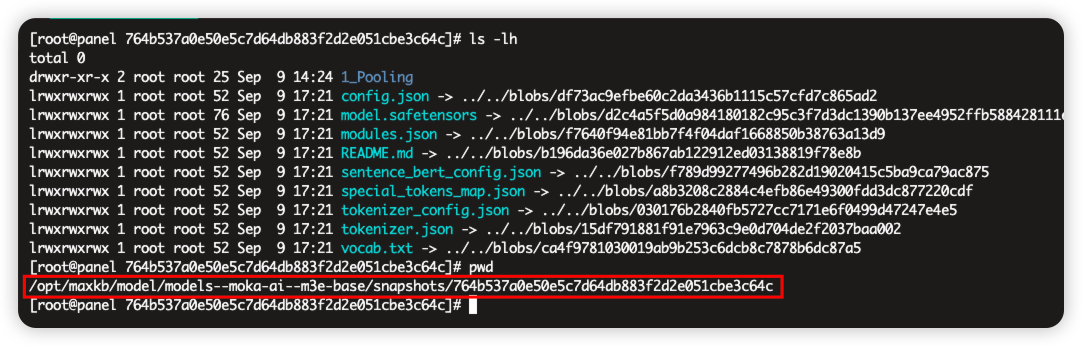
模型的位置必须在pytorch_model.bin、tokenizer_config.json、tokenizer.json 等这些文件下。