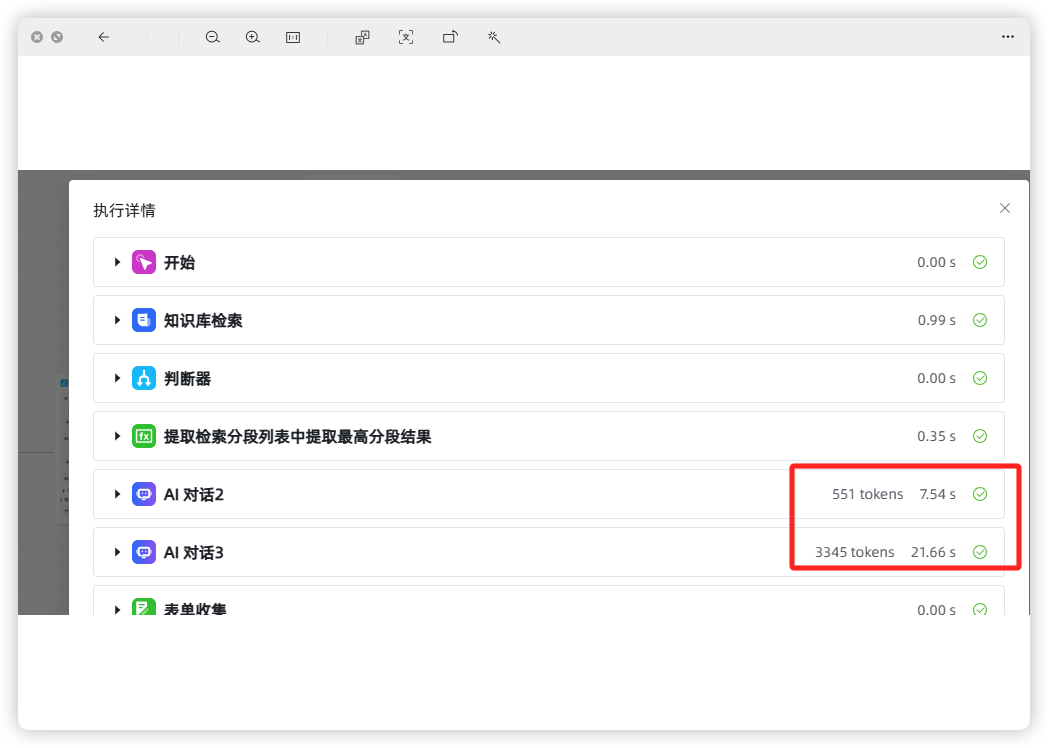
在一个工作流里多次调用模型,如何让每次调用模型都是单独的tokens计算,而不是总共的tokens计算
这个需要在这里看 ,外面只有一个汇总。
模型限制的最大tokens数,是总数不能超过限制数,还是每次模型调用分别不能超过tokens数
每次。。。。