在 MaxKB 会话中常遇到的模型“答不全”、“报错”等问题,原因归结为以下四种:
-
max_tokens设得过小,导致模型被迫提前终止; -
max_tokens设得过大,超过平台对该模型的硬上限,触发'Must be ≤ xxxx'报错; -
一次处理
token太多,报错'length of prompt_tokens must be less than max_seq_len '; -
单次会话消耗
token总长度触顶,出现'Your request exceeded model token limit'异常;
1. AI回答问题不全:max_tokens 设置不足
问题描述:AI 对话节点设置的 max_tokens 不够大,导致生成的内容被截断。
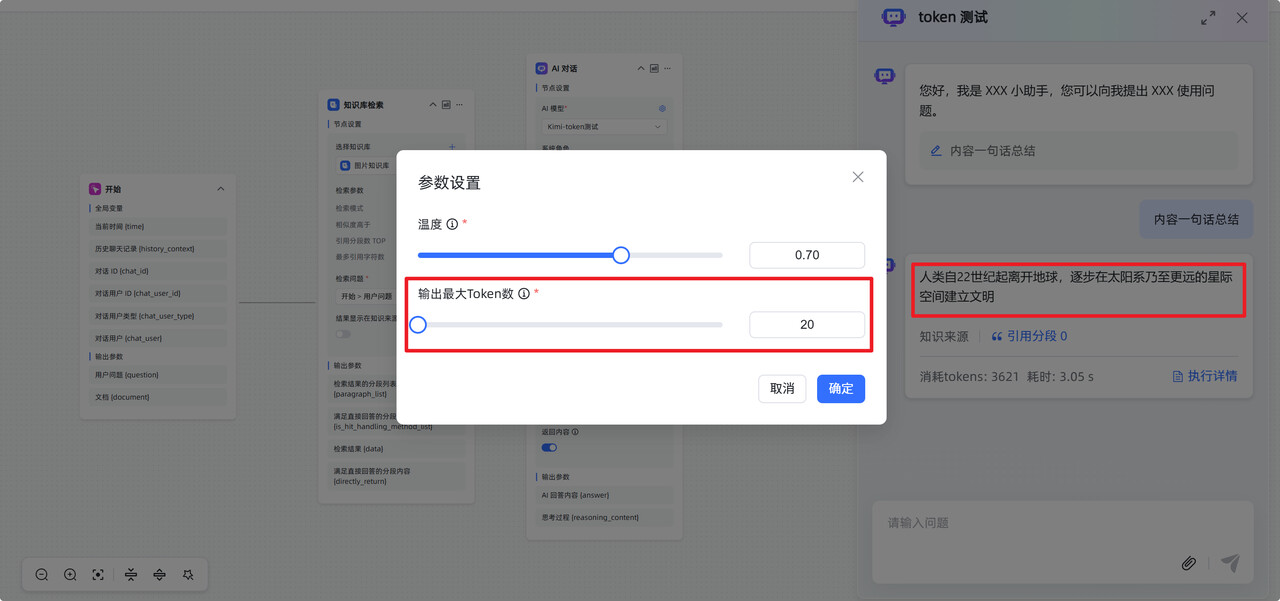
解决办法:适当调整
max_token 值。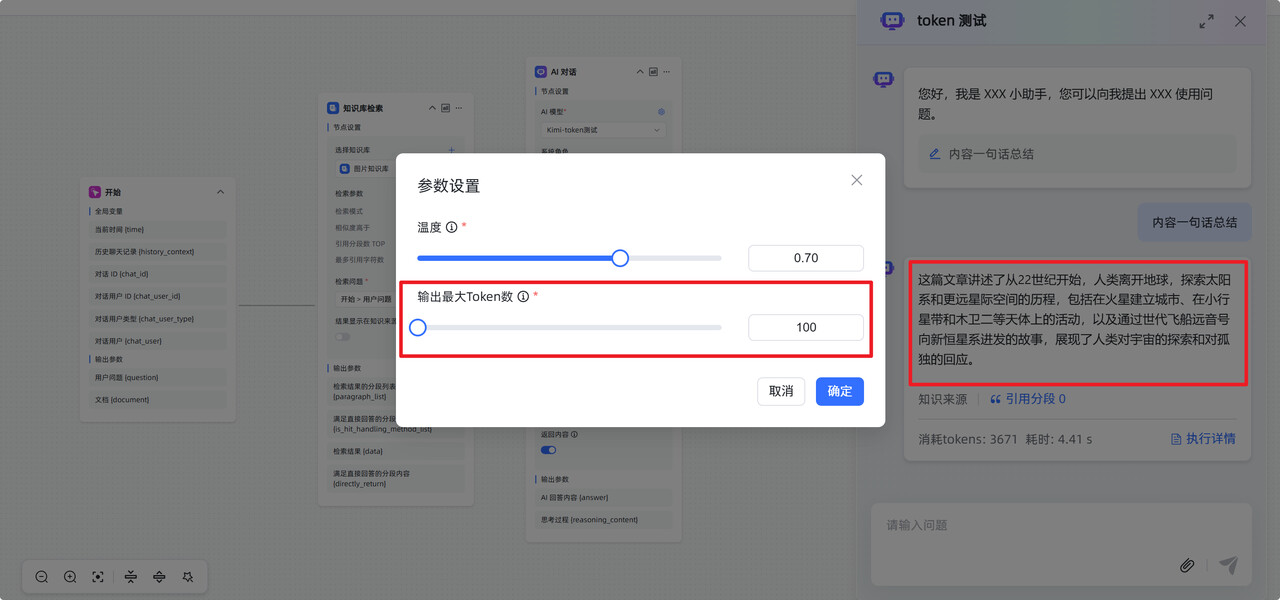
2. 报错:‘Must be less than or equal to xxxx’
问题描述:请求参数中 max_tokens设置过大,超过了平台(如:SILICONFLOW)对该模型允许的最大输出长度。
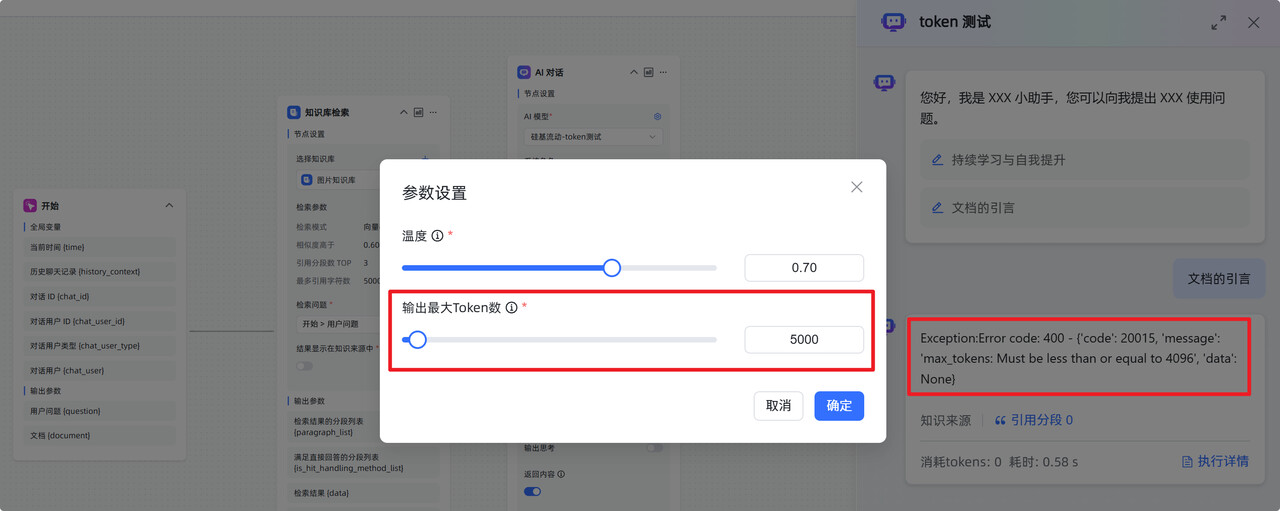
解决办法:将
max_tokens 降到平台对模型的限制以内。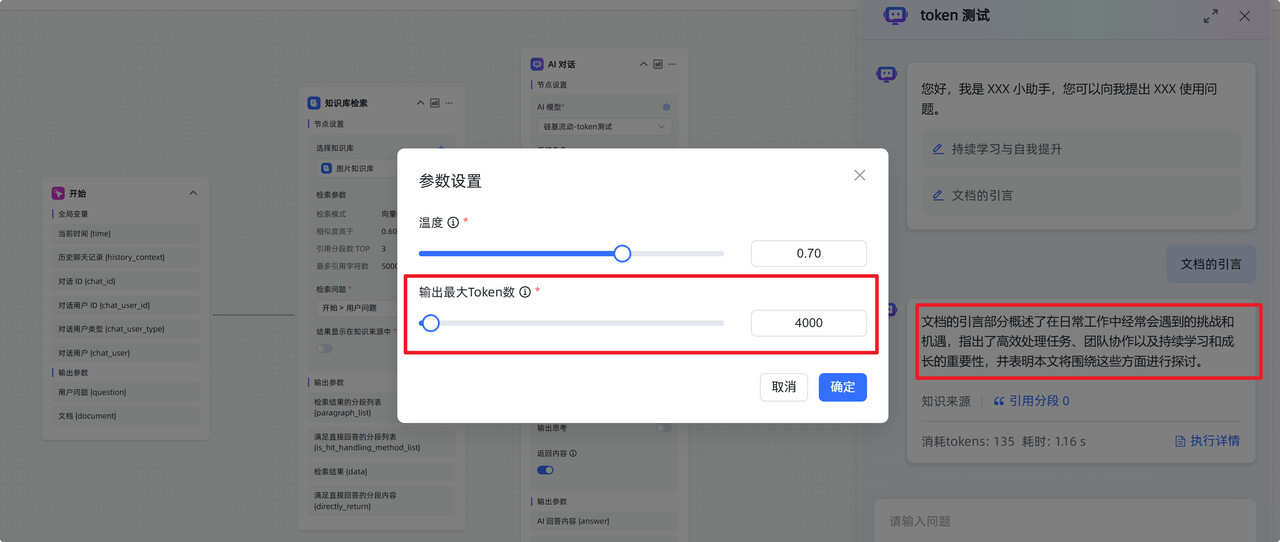
3. 报错:'length of prompt_tokens must be less than max_seq_len ’
问题描述:文档内容过多,一次处理的 token 数(包括输入和输出)超过模型的 max_seq_len 的硬限制。
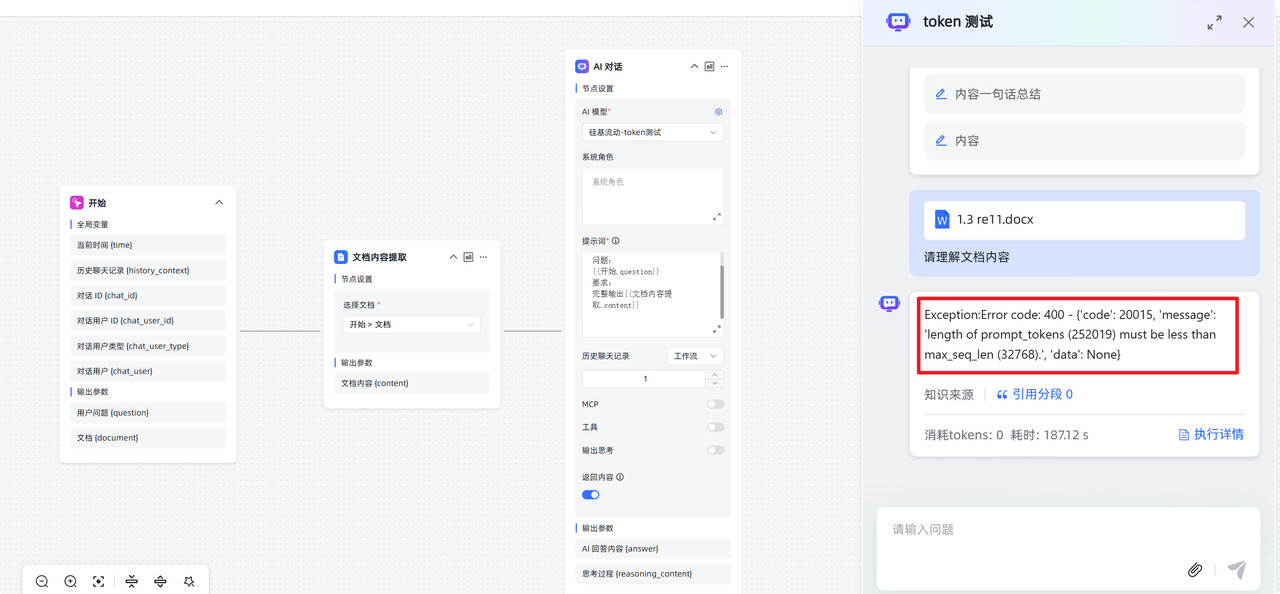
解决办法:缩短文档,或者换支持处理更长
token 的模型。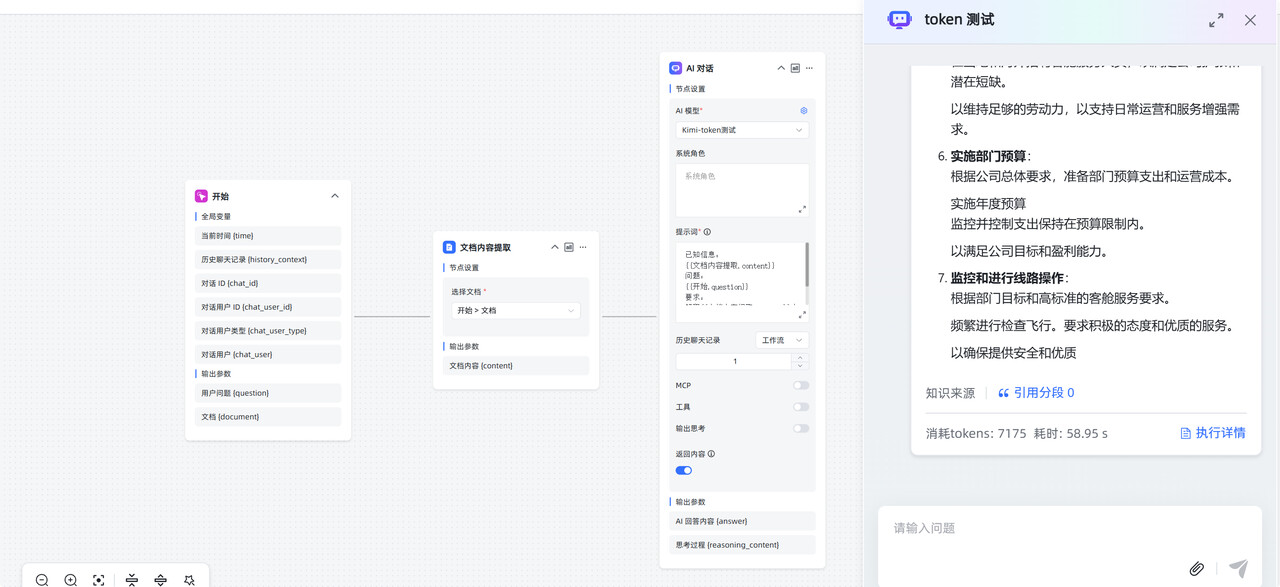
4. 报错:‘Invalid request: Your request exceeded model token limit: xxxx’
问题描述:整个请求上下文(系统提示 + 历史对话 + 检索结果 + 用户问题)的总 token 数 > 模型允许的最大上下文长度。
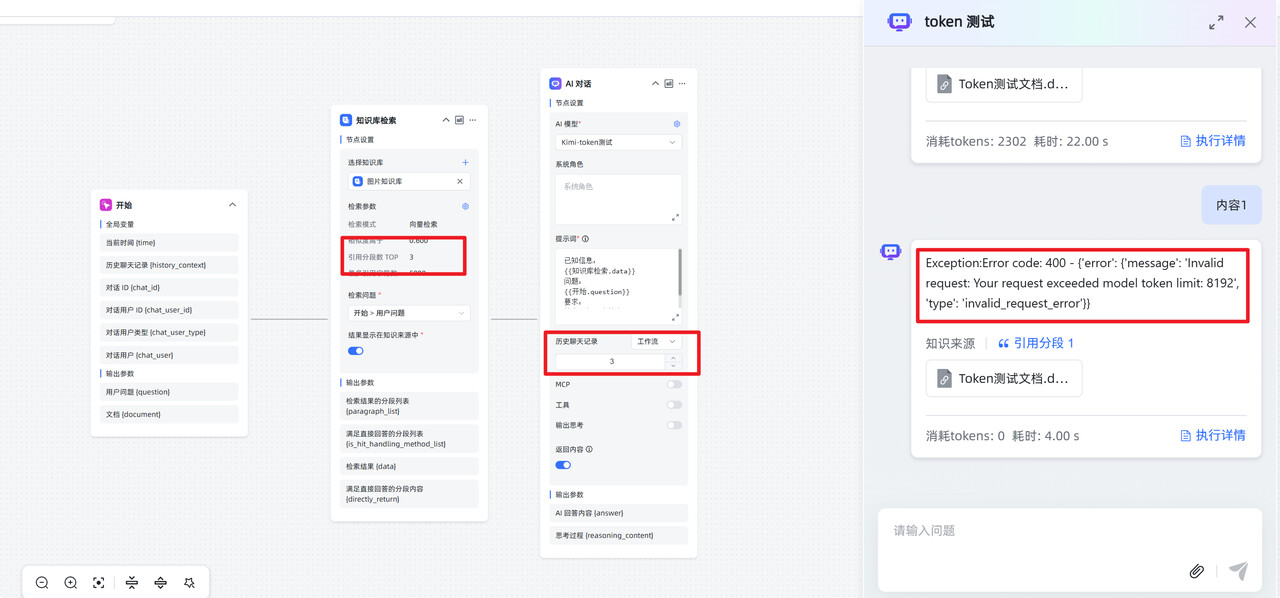
解决办法:减少引用分段数 TOP、减少历史聊天记录等。
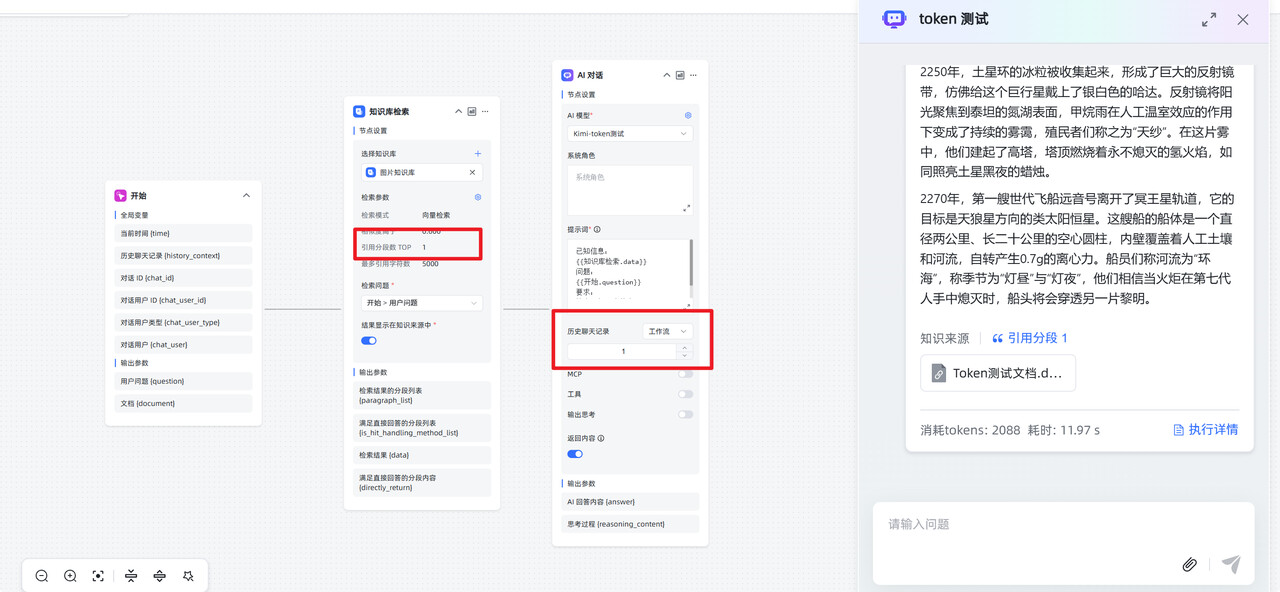
5. 其他原因
本地部署的模型本身可能不稳定、性能不高等,会导致回复中断、不回复等情况,建议更换模型或提高模型服务器配置。