我配置了语音模型,模型配置没有报错,但使用时没有生效也无错误,想查看哪里有问题
离线部署日志默认放在 /opt/maxkb/logs下
[in#0 @ 0x6982b40] Error opening input: Invalid data found when processing input
Error opening input file cache:pipe:0.
Error opening input files: Invalid data found when processing input
Traceback (most recent call last):
File “/opt/maxkb-app/apps/application/flow/workflow_manage.py”, line 381, in hand_event_node_result
current_result = node_result_future.result()
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/opt/maxkb-app/apps/application/flow/workflow_manage.py”, line 43, in result
raise self.e
File “/opt/maxkb-app/apps/application/flow/workflow_manage.py”, line 467, in run_node_future
result = self.run_node(node)
^^^^^^^^^^^^^^^^^^^
File “/opt/maxkb-app/apps/application/flow/workflow_manage.py”, line 473, in run_node
result = node.run()
^^^^^^^^^^
File “/opt/maxkb-app/apps/application/flow/i_step_node.py”, line 243, in run
result = self._run()
^^^^^^^^^^^
File “/opt/maxkb-app/apps/application/flow/step_node/text_to_speech_step_node/i_text_to_speech_node.py”, line 32, in _run
return self.execute(content=content, **self.node_params_serializer.data, **self.flow_params_serializer.data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/opt/maxkb-app/apps/application/flow/step_node/text_to_speech_step_node/impl/base_text_to_speech_node.py”, line 67, in execute
audio_segment = AudioSegment.from_file(temp_file)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/opt/py3/lib/python3.11/site-packages/pydub/audio_segment.py”, line 773, in from_file
raise CouldntDecodeError(
pydub.exceptions.CouldntDecodeError: Decoding failed. ffmpeg returned error code: 183
Output from ffmpeg/avlib:
ffmpeg version N-71064-gd5e603ddc0-static John Van Sickle - FFmpeg Static Builds Copyright (c) 2000-2024 the FFmpeg developers
built with gcc 8 (Debian 8.3.0-6)
configuration: --enable-gpl --enable-version3 --enable-static --disable-debug --disable-ffplay --disable-indev=sndio --disable-outdev=sndio --cc=gcc --enable-fontconfig --enable-frei0r --enable-gnutls --enable-gmp --enable-libgme --enable-gray --enable-libaom --enable-libfribidi --enable-libass --enable-libvmaf --enable-libfreetype --enable-libmp3lame --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-librubberband --enable-libsoxr --enable-libspeex --enable-libsrt --enable-libvorbis --enable-libopus --enable-libtheora --enable-libvidstab --enable-libvo-amrwbenc --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libdav1d --enable-libxvid --enable-libzvbi --enable-libzimg
libavutil 59. 27.100 / 59. 27.100
libavcodec 61. 9.100 / 61. 9.100
libavformat 61. 4.100 / 61. 4.100
libavdevice 61. 2.100 / 61. 2.100
libavfilter 10. 2.102 / 10. 2.102
libswscale 8. 2.100 / 8. 2.100
libswresample 5. 2.100 / 5. 2.100
libpostproc 58. 2.100 / 58. 2.100
[cache @ 0x70f1640] Statistics, cache hits:0 cache misses:1,日志显示的错误,这个如何解决?
看报错是显示读不到有效音频数据,这边输入的音频是正常输入吗?方便录个视频还是截图看看吗,还有这边maxkb的具体版本是多少呢?用的哪个语音识别模型
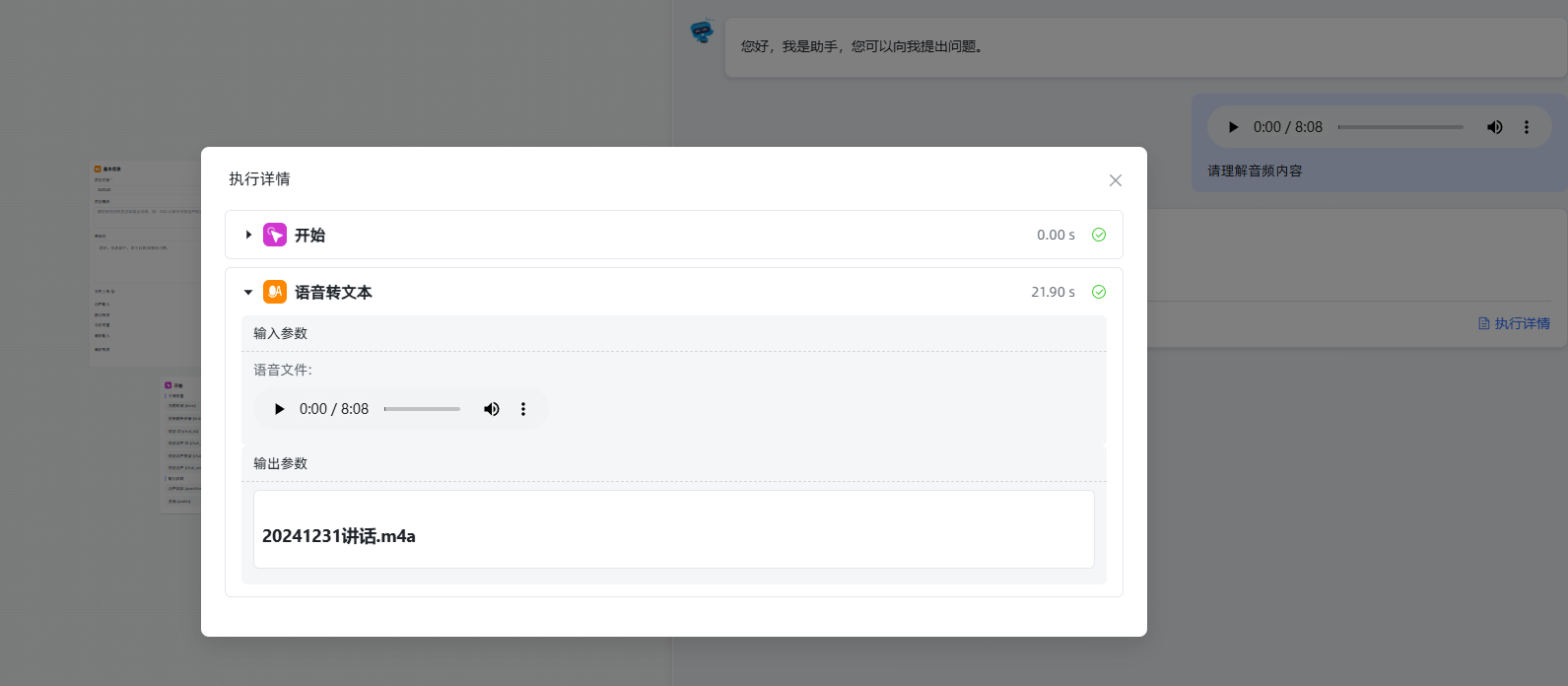
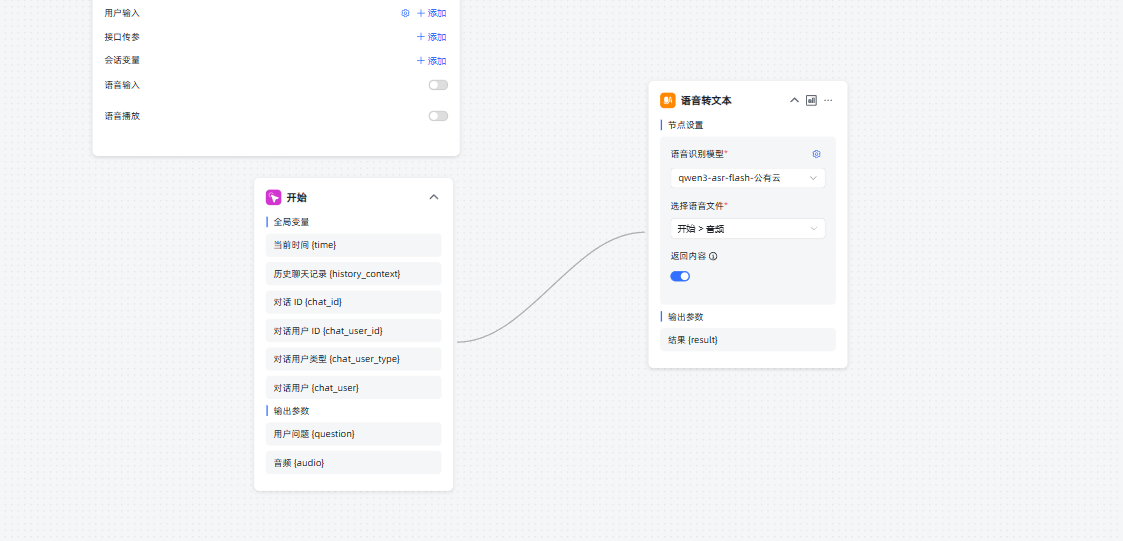
工作流怎么设计的,方便截个图吗
音频文件方便发一下吗,这边测试一下