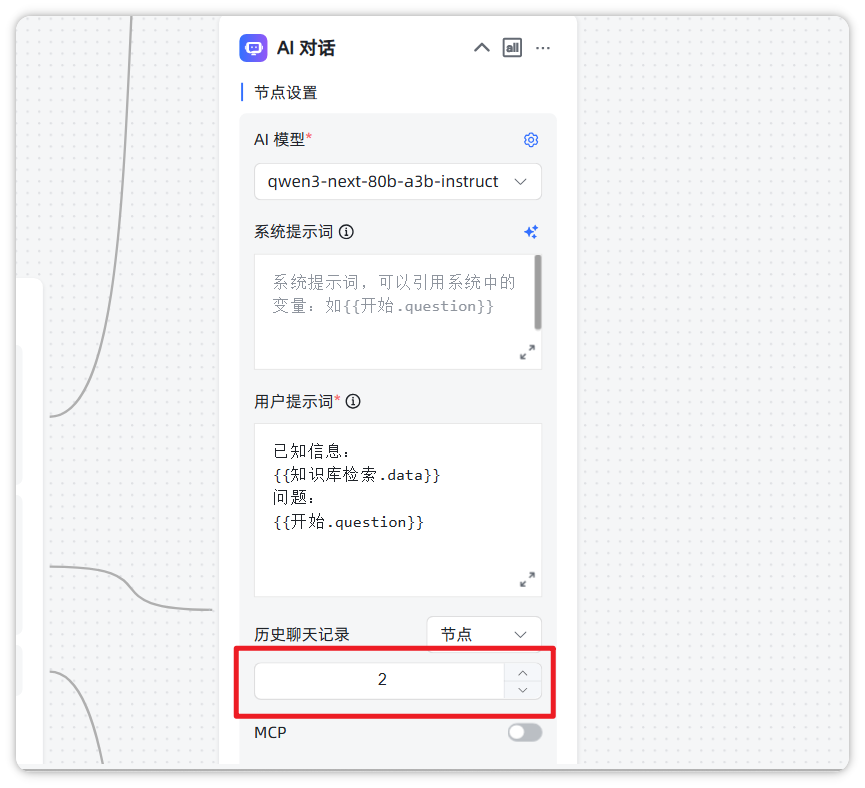
这是阿里官方调用示例,请问我要使用上下文功能在maxkb 2.4.1 中怎么使用
URL: Qwen-ASR API调用方法与参数-大模型服务平台百炼-阿里云-大模型服务平台百炼(Model Studio)-阿里云帮助中心
# ======= 重要提示 =======
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# 新加坡地域和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# === 执行时请删除该注释 ===
curl --location --request POST 'https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation' \
--header 'Authorization: Bearer $DASHSCOPE_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen3-asr-flash",
"input": {
"messages": [
{
"content": [
{
"text": ""
}
],
"role": "system"
},
{
"content": [
{
"audio": "https://dashscope.oss-cn-beijing.aliyuncs.com/audios/welcome.mp3"
}
],
"role": "user"
}
]
},
"parameters": {
"asr_options": {
"enable_itn": false
}
}
}'