各位伙伴,大家好,我在使用 MaxKB 的过程中遇到一个问题,想向各位请教一下。
目前的需求是: 我需要使用 第三方 AI 知识库 / 检索服务 来执行文档搜索,然后把检索结果交给 MaxKB 的后续流程(例如 AI Chat 节点)继续处理,让它能够正常展示:
- 引用的分段内容
- 文档标题
- 文档链接
- 相似度分数
- 其他元数据
但是第三方返回的 JSON 结构与 MaxKB 内置的“知识库搜索组件”输出格式并不一致,导致:
- MaxKB 的
多路回归 节点无法识别 score
- 文档链接不正确显示
- 分段引用无法触发
- 后续流程把内容当成普通文本处理
例如,第三方返回的结构类似这样:
{
"id": "paragraph_0",
"document_id": "abc123",
"content": "...",
"score": 0.85,
"source": {
"url": "https://doc.abc.com/xxx"
}
}
但我观察到 MaxKB 似乎需要的是另一种格式,比如包含:
-
data, paragraph_list 数组
is_hit_handling_method_listdirectly_return- 以及其他字段
所以我想请教大家:
如果想手动模拟 MaxKB 的知识库搜索输出,应该按照什么格式构造 JSON?
有没有官方或社区认可的 标准输出示例? 或者有没有人成功把第三方检索结果适配成 MaxKB 能正确识别的格式?
希望能看到一个完整的示例,包括:
- 正确的字段名
-
data 数组的结构
- 文档链接应该放在哪里
- 如何让 AI Chat 正确展示引用
非常感谢大家的经验分享!
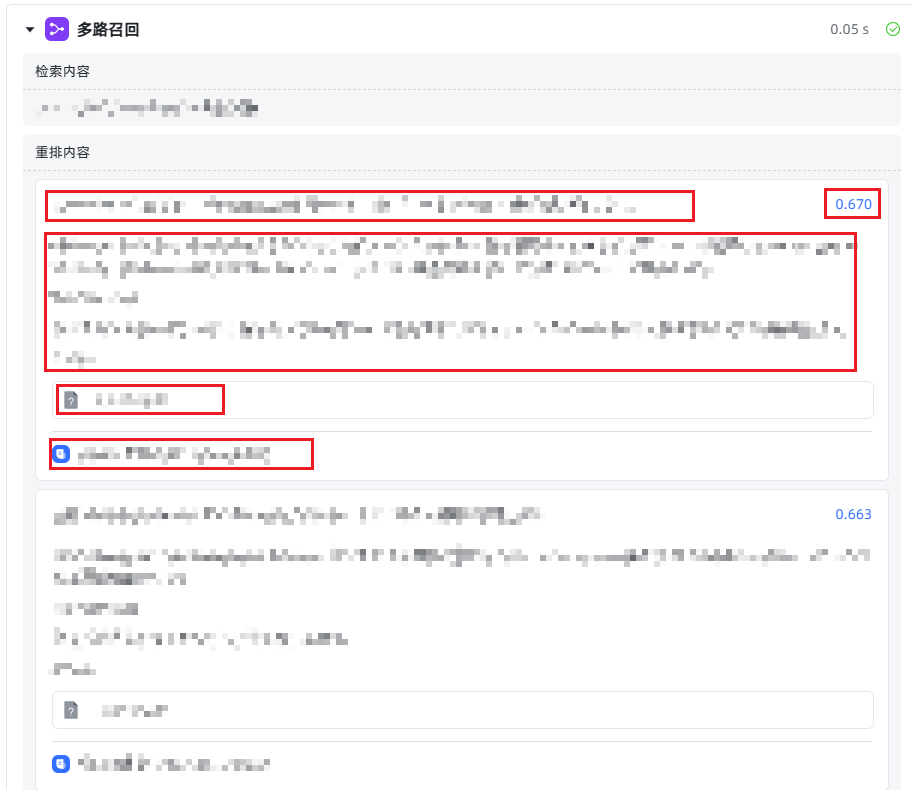
伙伴们,我找到正确的JSON格式了。
能够被多路回归组件正确识别大部分信息的结构如下
[{
"create_time": datetime,
"update_time": datetime,
"id": str, #UUID
"document_id": str, #UUID
"document_name": str, # UUID
"knowledge_id": str, #UUID
"chunk_index": int, # zero based chunk index
"title": str, # chunk title
"content": str, # chunk content
"is_active": boolean, # true
"position": int, # one based rank index.
"hit_num": int, # zero based rank index
"chunks": [], # chunks
"knowledge_name": string, # knowledge source name
"knowledge_type": int, # looks like an enum 0 is normal KB, 1 is online KB
"meta": {
"allow_download": boolean,
"source_file_id": string # * Optional,file id or path name
"source_url": string # * Optional, file URL.
},
"hit_handling_method": "optimization", # string
"directly_return_similarity": float, # 0 - 1
"similarity": float, # 0 - 1
"is_hit_handling_method": boolean
}]
如上图,大部分信息可以完整显示。
注意:如果下载地址是绝对地址或URL,需要讲meta中的source_file_id 更换为 source_url.