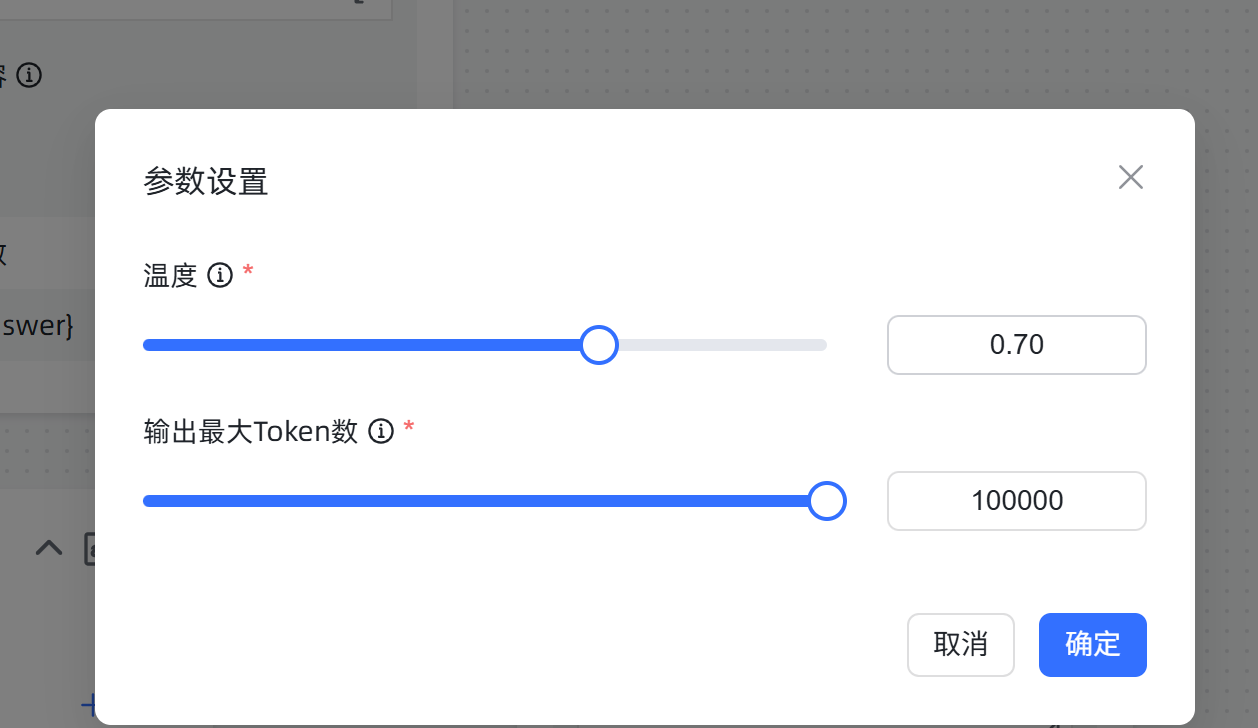
模型的max_token开到最大了吗,输出截断可能是这个最大输出token截断了
我是开到了最大,拉满了,这会导致两个不同的对话同时占用输出token总数吗?;
什么模型?得看你模型支持的最大token数是多少。但是每次问答都是由模型进行生成的,我看你温度调的也挺高,较高的数值会使输出更加随机,导致两次的回答字数不一致,最终还是超过了你的最大token数