将输入的问题,单独直接在ollama中对话则可以完整回复。是不是Maxkb调用ollama有设置超时时间或者响应体大小限制 会直接中断,这问题卡着了,没找到有这方面的配置
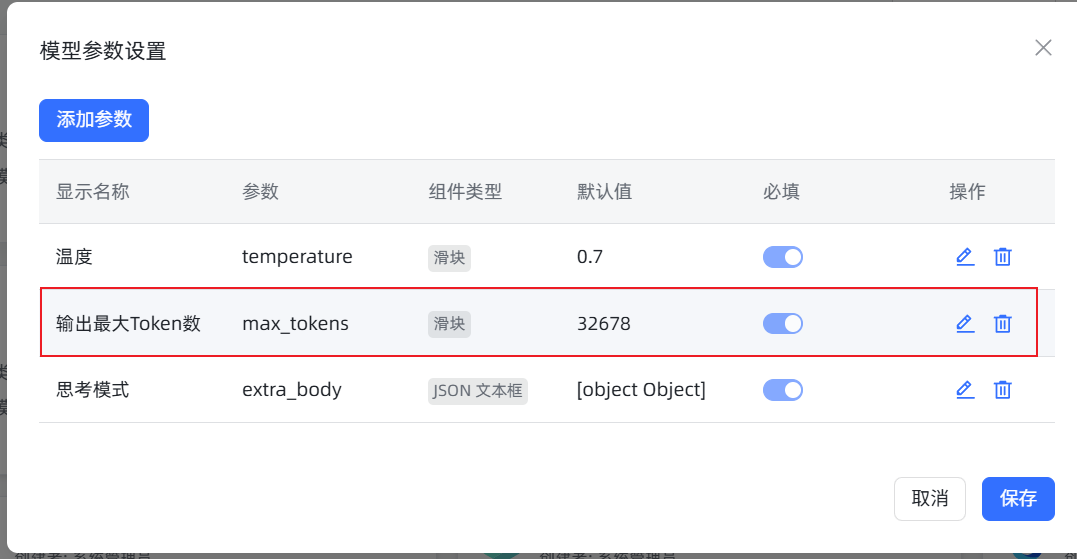
可以检查模型的max_tokens参数是不是过小,导致输出不完整