1. 背景说明
在接口测试或者自动化测试工作中,大家一定会遇到登陆需要验证码处理的问题。在功能测试中,手动测试下即可,但是在自动化测试中,一直是个比较难处理的问题。很多测试人员的处理方式都比较粗暴,要不后台设置万能验证码,要不后台生成永久TOEKN跳过验证码环节,或者有的直接测试环境取消验证码,说实话这种方式也非常实用,但是无形中不仅是测试的遗漏也具备一定的安全隐患。
目前验证码主要有以下的种类:
- 可以随机变换的图片文字类验证码;
- 手机短信验证码,发送到指定的手机号中;
- 通过语音播报的语音验证码;
- 随机数字、字母和中文组合而成的验证码动态嵌到MP4,flv等格式的视频中;
- 还有通过图片等方式呈现出的验证码。
而OCR为图像识别技术,核心技术包含两方面,一是目标检测模型检测图片中的文字,二是文字识别模型,将图片中的文字转成文本文字。
所以利用OCR识别验证码,将识别的验证码中文本通过参数变量方式带入登陆接口,就能够实现带验证码接口的自动化登陆。
2. ddddocr项目
2.1 项目简介
ddddocr是一个开源图片识别库,用于识别验证码。爬虫界大佬sml2h3开发,识别效果非常不错。Github地址为:https://github.com/sml2h3/ddddocr
目前ddddocr支持以下几种验证码的识别:
滑块验证码

点选类验证码
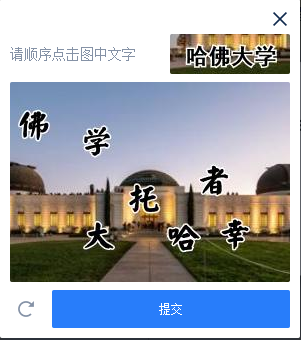
字母数字验证码

2.2 部署安装
在安装MeterSphere服务器中执行以下安装命令,或者准备一台带docker环境的服务器。
git clone https://github.com/sml2h3/ocr_api_server.git
cd ocr_api_server
# 修改entrypoint.sh中的参数,具体参数往上翻,默认9898端口,同时开启ocr模块以及目标检测模块
# 编译镜像
docker build -t ocr_server:v1 .
# 运行镜像
docker run -p 9898:9898 -d ocr_server:v1
# 验证是否安装成功
可以通过直接GET访问http://{host}:{port}/ping来测试,如果返回pong则启动成功
3. 具体操作说明
3.1 实现思路
下载验证码图->上传ddddocr识别->取回识别文字-带入接口登陆
3.2 确认刷新或者下载验证码的接口
确认刷新验证码的接口,可以通过浏览器F12进行抓包,比如下面刷新验证码或者下载验证码的接口为:
https://xxx/api/service/sdk/external/login/captcha
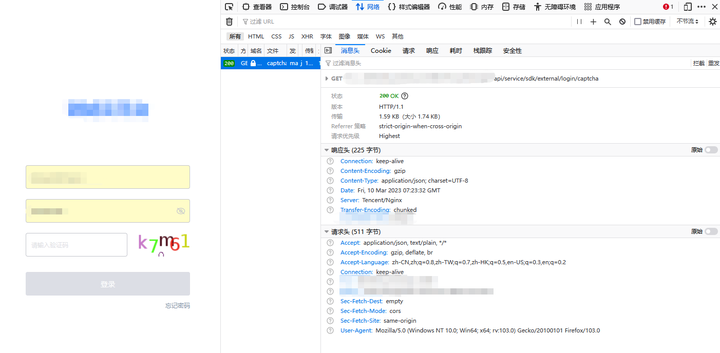
在接口中请求此接口,并且用后置参数提取方式保存验证码对应的key值。
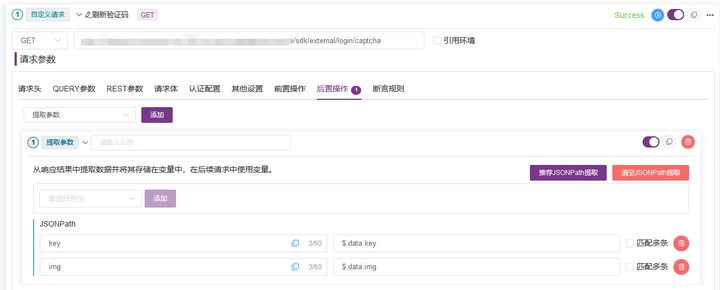
3.3 下载验证码并且进行base64转码
通过访问具体的下载接口的URL后,我们需要将返回的验证码进行下载并且进行base64转码,此处需要利用MeterSphere的后置脚本能力。
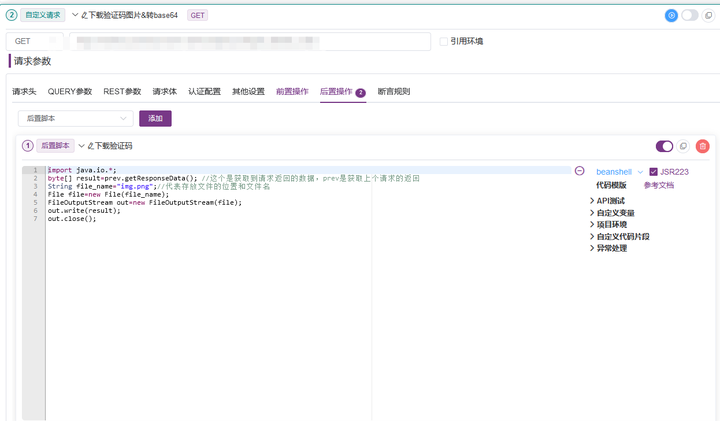
下载验证码后置脚本(beanshell脚本):
import java.io.*;
byte[] result=prev.getResponseData(); //这个是获取到请求返回的数据,prev是获取上个请求的返回
String file_name="img.png";//代表存放文件的位置和文件名
File file=new File(file_name);
FileOutputStream out=new FileOutputStream(file);
out.write(result);
out.close();
验证码图片转base64脚本(python脚本):
import base64
def img_to_base64(img_path):
with open(img_path, 'rb')as read:
b64 = base64.b64encode(read.read())
return b64
img_b64 = img_to_base64('img.png')
vars.put("img_b64", img_b64)#将转成base64的验证码存为img_b64变量
log.info(img_b64)
3.4 调用OCR接口,进行验证码识别
目前ddddocr支持以下几种识别和验证:
# http://{host}:{port}/{opt}/{img_type}/{ret_type}
# opt:操作类型 ocr=OCR det=目标检测 slide=滑块(match和compare两种算法,默认为compare)
# img_type: 数据类型 file=文件上传方式 b64=base64(imgbyte)方式 默认为file方式
# ret_type: 返回类型 json=返回json(识别出错会在msg里返回错误信息) text=返回文本格式(识别出错时回直接返回空文本)
# 例子:
# OCR请求
# resp = requests.post("http://{host}:{port}/ocr/file", files={'image': image_bytes})
# resp = requests.post("http://{host}:{port}/ocr/b64/text", data=base64.b64encode(file).decode())
# 目标检测请求
# resp = requests.post("http://{host}:{port}/det/file", files={'image': image_bytes})
# resp = requests.post("http://{host}:{port}/ocr/b64/json", data=base64.b64encode(file).decode())
# 滑块识别请求
# resp = requests.post("http://{host}:{port}/slide/match/file", files={'target_img': target_bytes, 'bg_img': bg_bytes})
# jsonstr = json.dumps({'target_img': target_b64str, 'bg_img': bg_b64str})
# resp = requests.post("http://{host}:{port}/slide/compare/b64", files=base64.b64encode(jsonstr.encode()).decode())
本次主要采用OCR请求接口:http://{host}:{port}/ocr/b64/json,并且通过后置参数提取方式提取相应识别到的验证码文本。
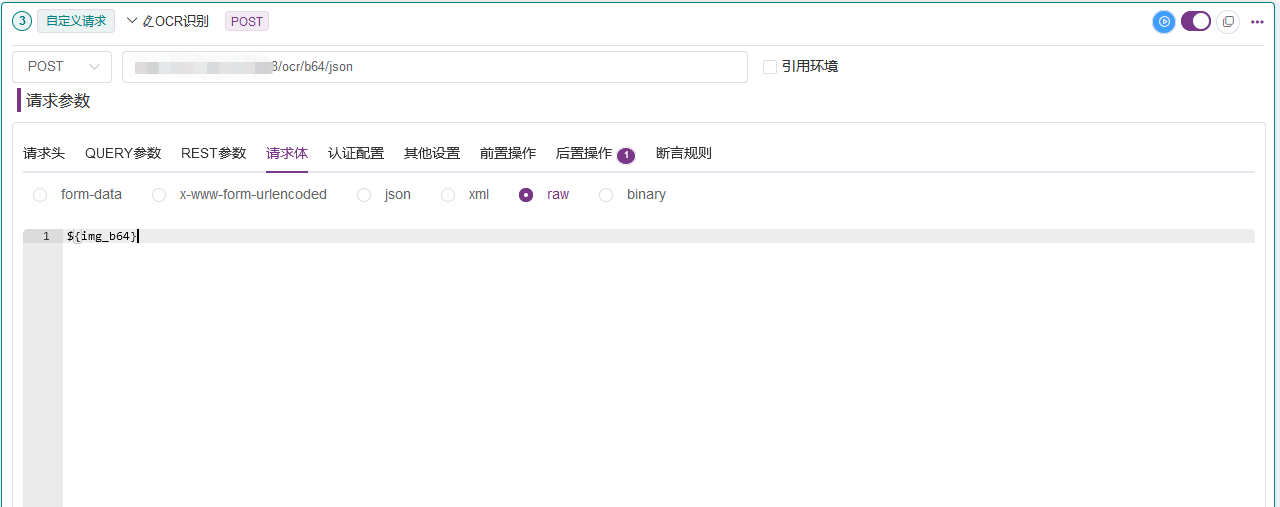
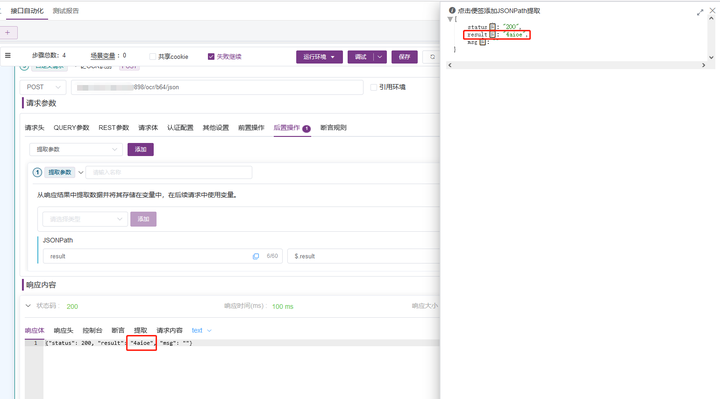
3.5 最终将提取的验证码文本,通过变量带入接口登陆中。
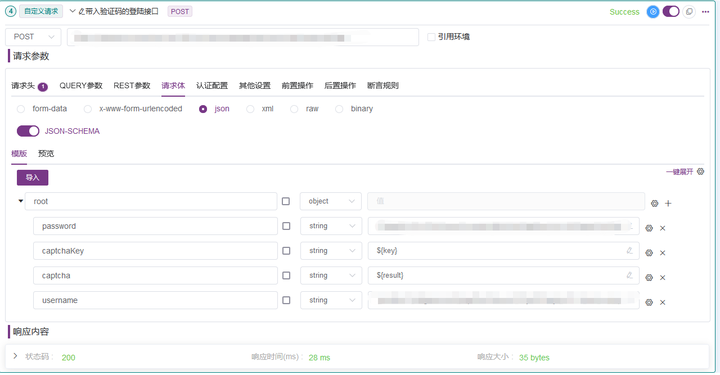
4. 整体运行效果

目前ddddocr对白底的验证码识别较好,如果有一些特殊的验证码在识别准确率上有所欠佳,需要进行相应的模型训练才行,训练方式详见:https://github.com/sml2h3/dddd_trainer。有趣的可以深入研究。