用的什么LLM模型? 应用的提示词可以简化一下,不要携带太多内容。
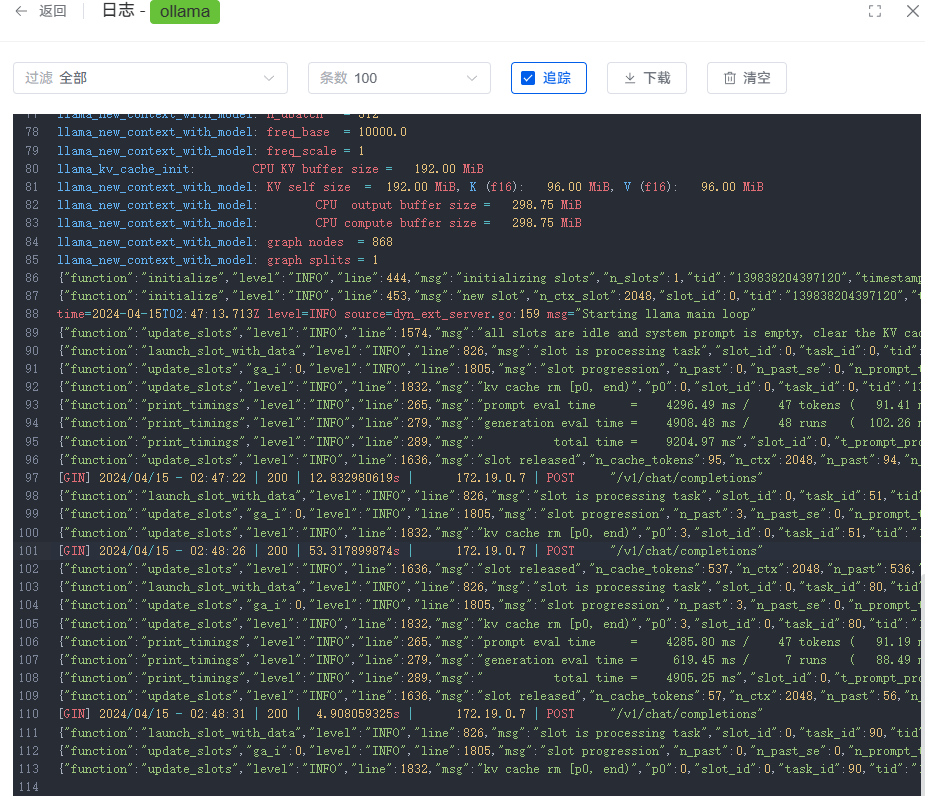
qwen:0.5b-chat,才395M
就一个你是谁?已经很简单了吧 ![]()
机器配置是多少? 感觉是配置不够跑不动,响应很慢。
把提示词内容减小,应用设置中把 提示词 改成: {question}
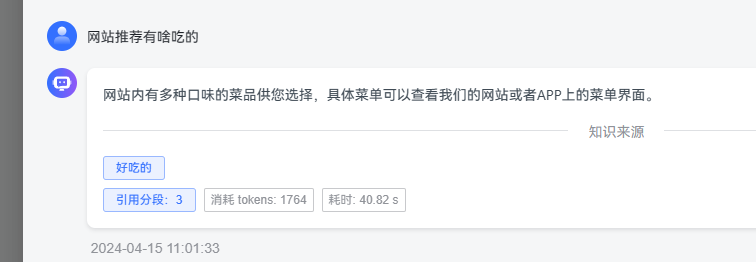
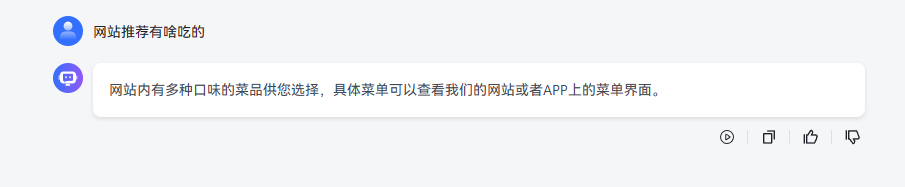
引用的分段内容会根据提示词生成 prompt 发给大模型,回答内容直接返回 AI 模型回复的。
用户端对话回答不显示引用的知识库来源,可以加上吗?
你可以先在应用设置的调试预览中提问测试,这里有知识来源。
增加功能预计要 1-2 个功能版本迭代。
我如果想在本地添加的话,需要改哪里呢?
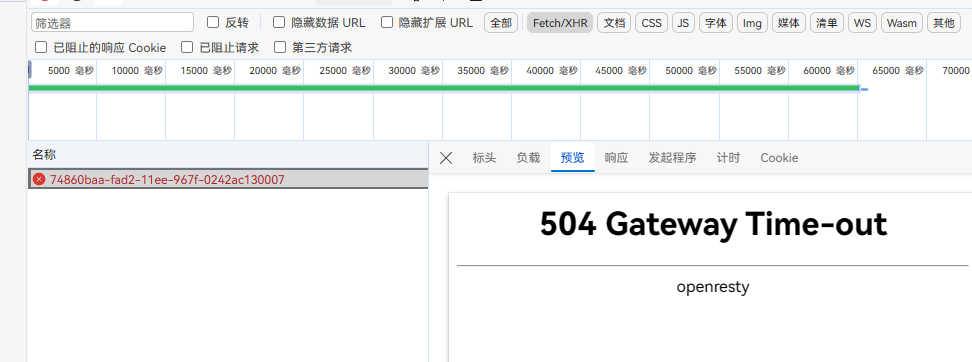
模型返回的错误信息。
排查一下:
1、可以现在模型管理中保存一下 llama2 模型,是否能正常保存成功。
2、如果能保存成功,优化应用的提示词只保留{question}, 然后提问测试看是否正常回答。
我想问一下这个qwen:0.5b-chat怎么弄上去的
在模型管理中添加 Ollama 模型,基础模型中自定义输入:qwen:0.5b 回车。