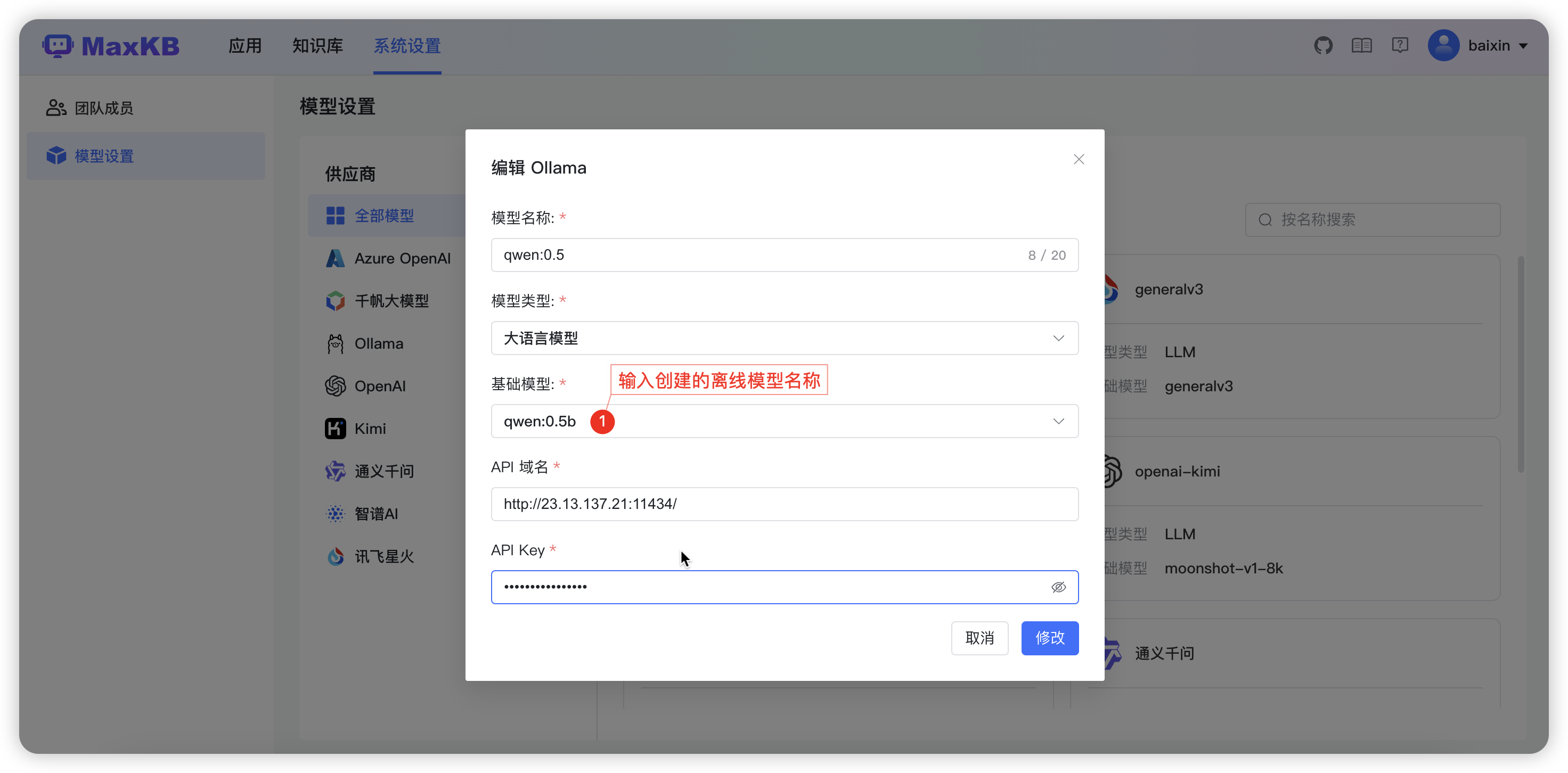
如果你没有全离线部署本地 LLM 模型的需求,请直接查看如何在线添加本地LLM模型
本文以在 Ollama 中离线部署 qwen:0.5b 模型为例。
1. 下载模型
访问 huggingface 下载 qwen1_5-0_5b-chat-q5_k_m.gguf 模型。
https://huggingface.co/Qwen/Qwen1.5-0.5B-Chat-GGUF/tree/main
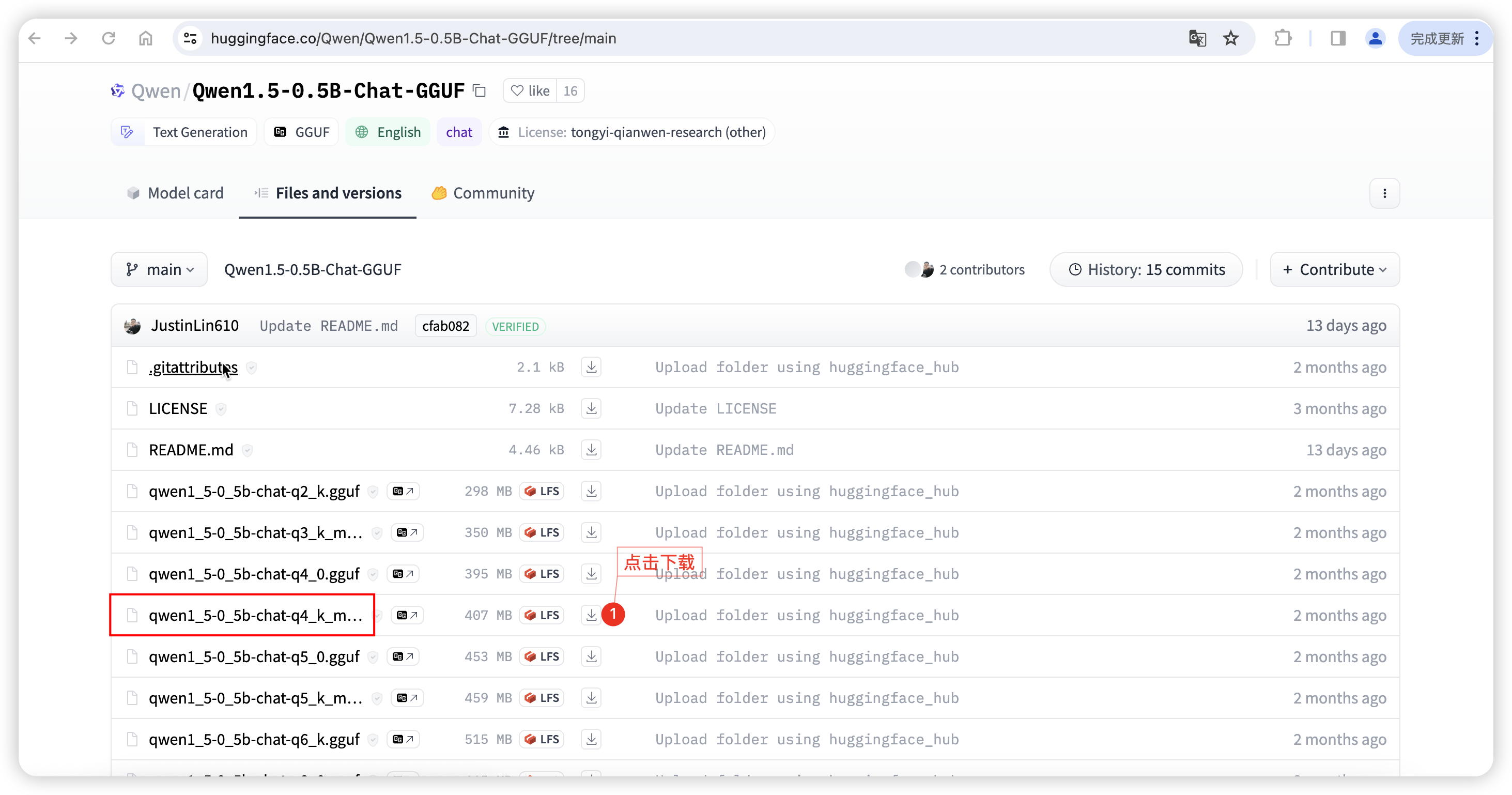
2 上传 Qwen1.5-0.5B-Chat-GGUF 模型离线文件到 Ollama 所在服务器
3 创建Ollama Modelfile
创建一个名为 Modelfile 的文件,内容如下:
FROM ./qwen1_5-0_5b-chat-q5_k_m.gguf
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|im_end|>"
说明:不同模型的 Modelfile 内容不同,可参考 Ollama 官网 参数设置 。

4 在Ollama中创建模型
执行以下命令,创建模型:
ollama create qwen:0.5b -f Modelfile
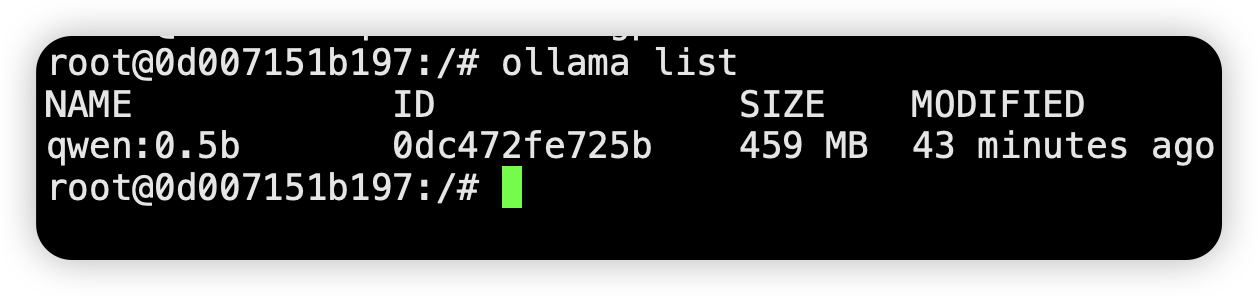
执行以下命令,确认模型存在:
ollama list