maxkb向量召回速度是否还能优化?或者给些监控指标?
开始以为大模型返回的慢 但是我nvidia-smi监控gpu的时候 显存只占一半利用率也不高 并且gpu一转起来立马就返回内容了 给我的感觉是maxkb有点慢
总体回答需要10s以上
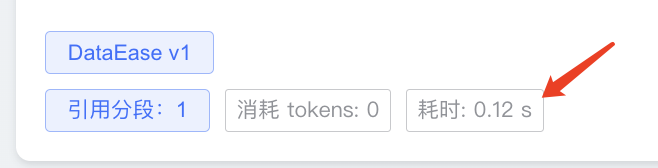
maxkb向量召回基本都在毫秒级别。下图是直接回复知识库内容的耗时。也就是 maxkb召回分段的耗时。
我这边离线服务器上部署的MaxKB,召回速度很慢,200条不到的EXCEL,召回耗时达到8s
maxkb向量召回速度是否还能优化?或者给些监控指标?
开始以为大模型返回的慢 但是我nvidia-smi监控gpu的时候 显存只占一半利用率也不高 并且gpu一转起来立马就返回内容了 给我的感觉是maxkb有点慢
总体回答需要10s以上
maxkb向量召回基本都在毫秒级别。下图是直接回复知识库内容的耗时。也就是 maxkb召回分段的耗时。
我这边离线服务器上部署的MaxKB,召回速度很慢,200条不到的EXCEL,召回耗时达到8s