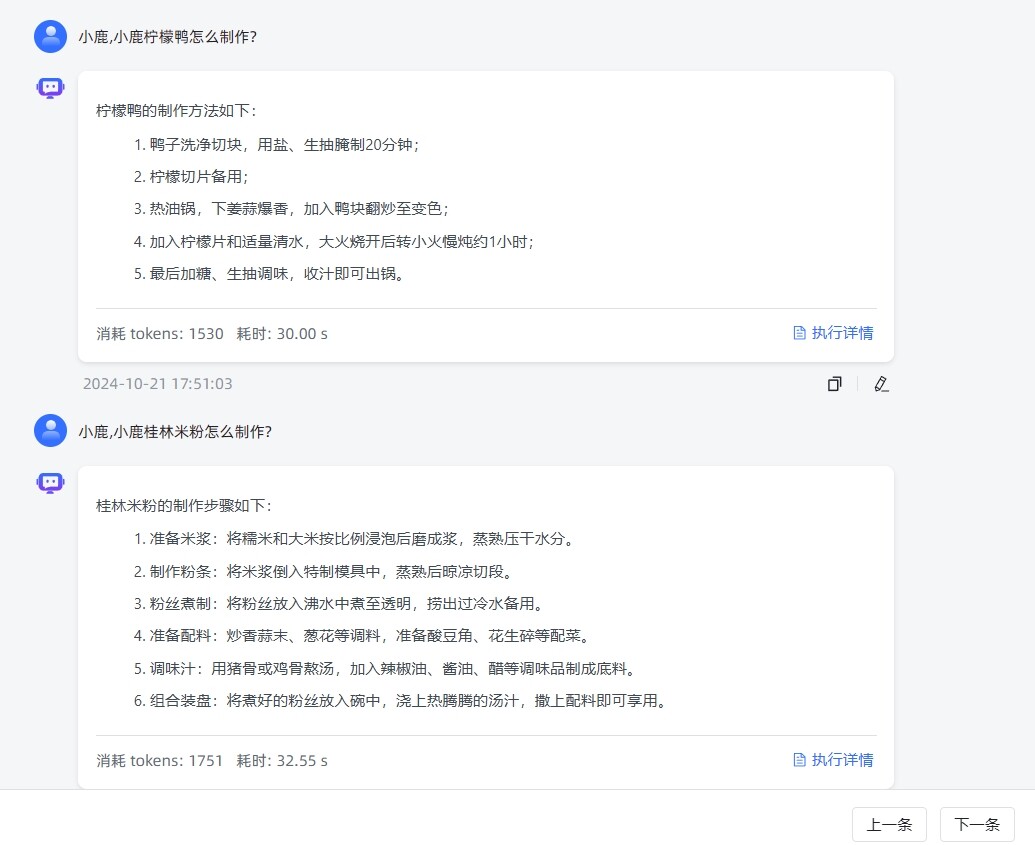
调试或者演示模式能很快的响应回答,但是通过API来调用会非常的耗时,慢!!!这是啥原因?电脑配置是i9-13900K,内存128G,显卡4090
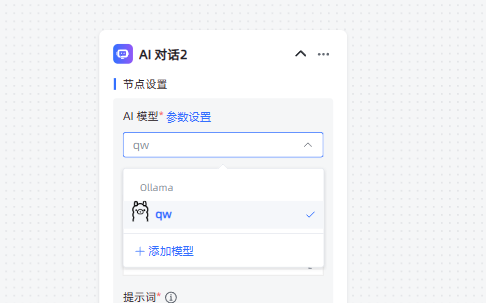
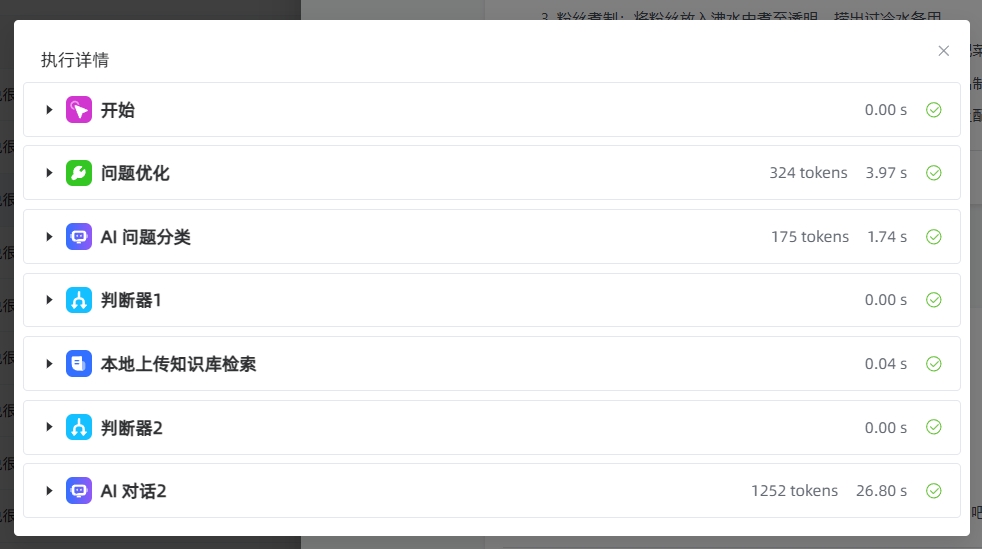
【AI 对话2】的配置参数详情是?使用了什么模型?是否有并发?
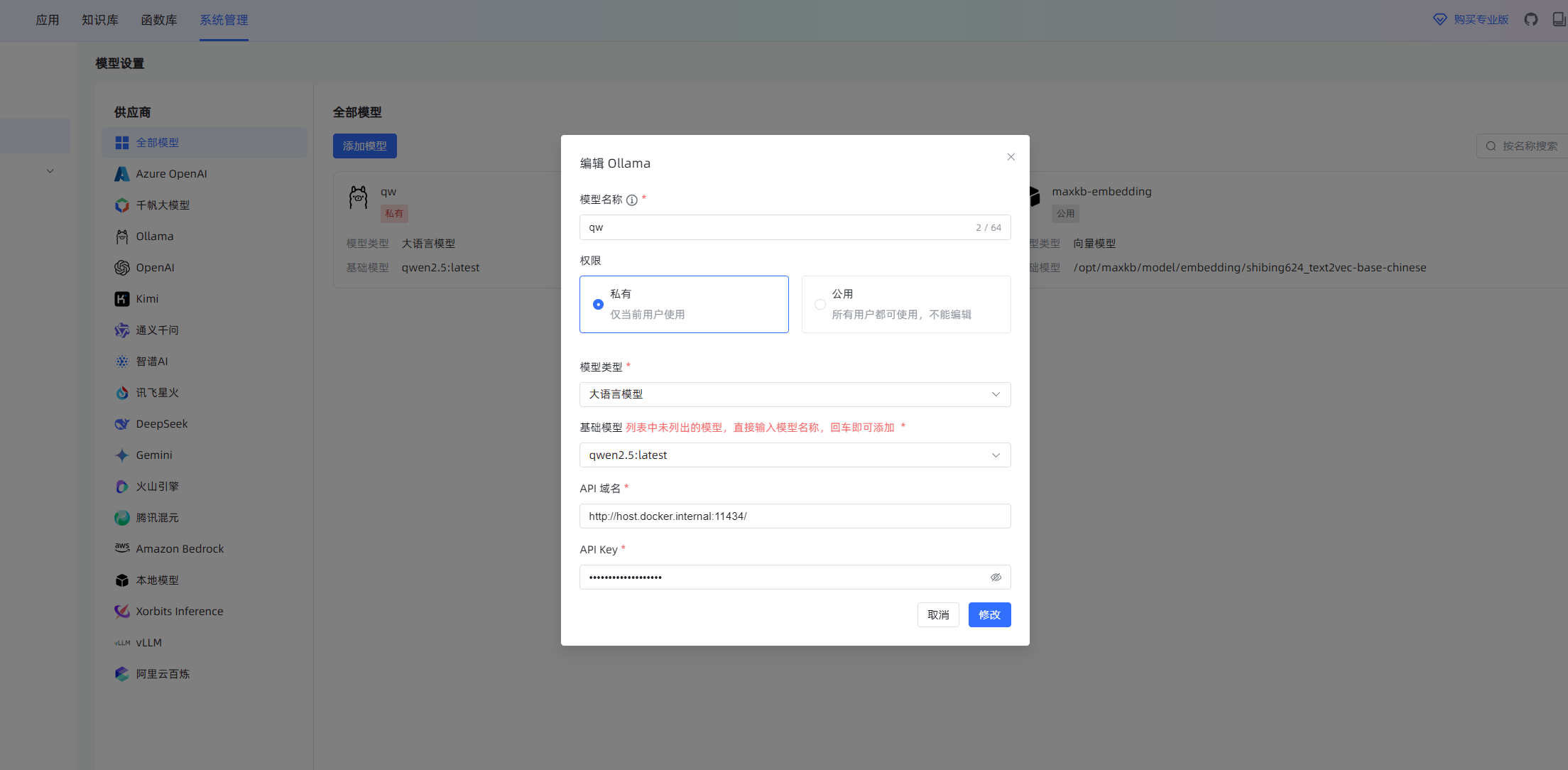
我所有的AI对话都只使用了一个ollama模型,电脑系统是Win10。
对于同一个问题,调试和API调用时间会相差多少?使用API调用时,调用地址是否为域名,如果是,可以使用纯IP调用对比下。
确认 ollama 使用了gpu进行加速?