shibing624/text2vec-base-chinese的向量化结果与官网上的例程的结果不一致,为啥?
您好,方便截图说明下么?
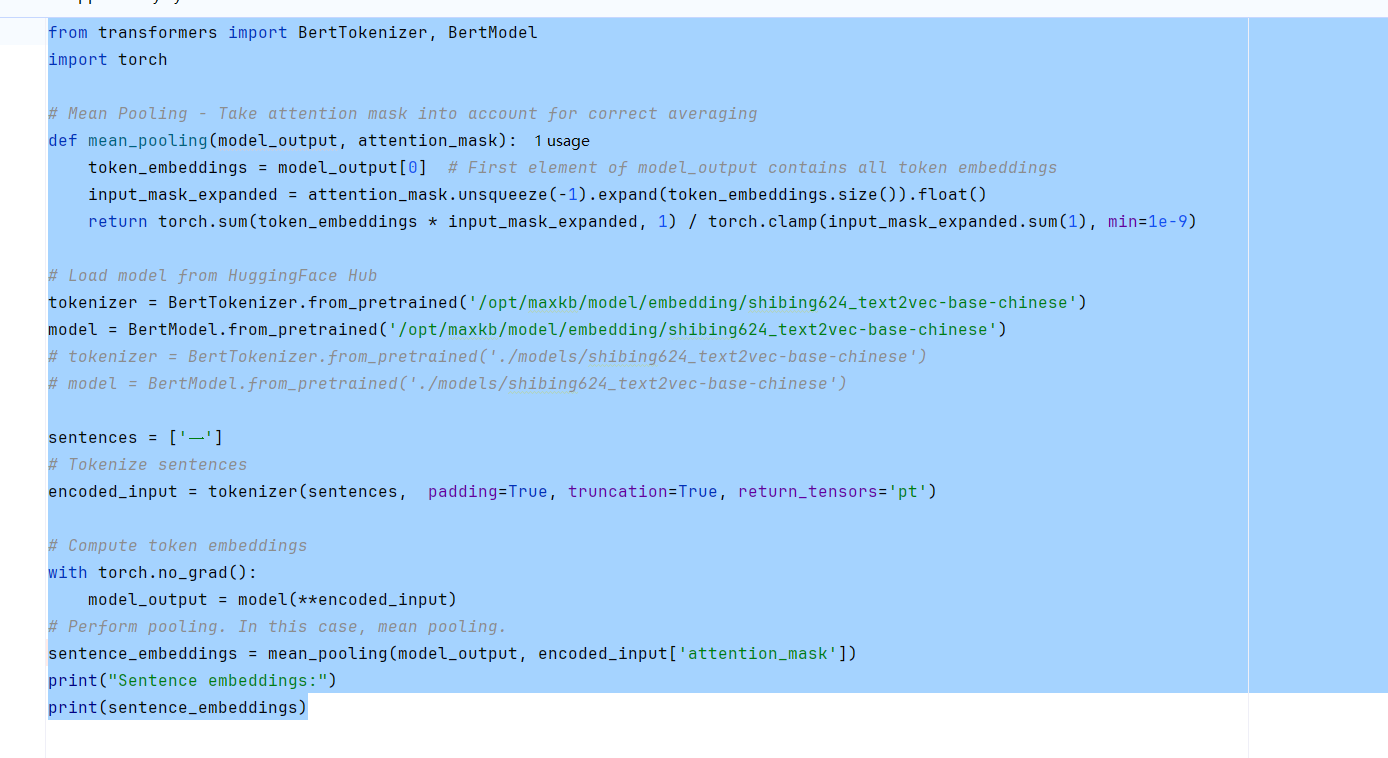

这是参照官网哪个例程处理的呀,能否发个链接出来?
原来是根据这个模型github官网的示例在进行向量化~
这句话又是什么意思呢?不太好理解。
首先,我在本地建了一个txt文件,文件中,只输入一个汉字“一”。
然后,我把该文件导入知识库,进行向量化处理。
最后,从pg数据库的embedding表中,字段embedding去验证本地根据官网生成的结果比较,发现不一致。
不一致的原因,我猜是outputs.last_hidden_state的汇总策略不同,但是从maxkb的源码中,我也没有找到该处理,比较好奇。